| February 2009 Index | Home Page |
Editor’s Note: The contributions of the LISTENER to language learning can and will be extensive. It is hoped that this project receives all of the academic and fiscal support required to fully realize its potential. Dr. Aguilar is to be congratulated on this research.
LISTENER: A New Personalized Multimedia Interface for Ubiquitous Learning
Gabriela Aguilar
Mexico
Abstract
The present paper introduces a new personalized multimedia interface for ubiquitous learning called LISTENER. This interface will consist of headphones and microphone, and a special device to input the document to be read. LISTENER will consist of three main processes. These are SPEBC (an adaptive computer-based assessment system), the content analysis module and the Natural Language Processing Module. On one hand, students will be able to interact with LISTENER by inputting spoken text or by inputting a textbook, paper, etc and SPEBC will generate questions based on request in order to assess the student’s understanding levels. On the other hand, the content analysis module will ask questions to the students about the omitted information in their answers. The Natural Language Processing Module will allow the input and output of data through the processing of speech synthesis and speech recognition, as an alternative media.
Keywords: Ubiquitous learning, Questions Generator System, Multimedia interface, Content Analysis of Written Text, Formative Assessment, Assessment of Multiple-choice and Open-ended Questions, Spoken Dialogue System.
Introduction
The present work introduces LISTENER, a new personalized multimedia interface for ubiquitous learning. LISTENER is the result of the improvement of SPEBC (Author, et al., 2006), an adaptive computer-based assessment system and of the content analysis of written text.
The first prototype of SPEBC was implemented. This is the Factual Questions Generator System (FQGS) (Author, et al., 2008). The FQGS was implemented to prove the feasibility of the questions generation approach. When the questions generated by the FQGS were being analyzed, the author realized that for some well-formed questions, there were no answers in the text document given as an input. So the author came up with the idea that this kind of questions can be very useful for users when they are writing a paper or analyzing a software requirement specification or useful for learners when they are writing an essay or answering an open-ended question. The generated questions without answer will be filtered by the content analysis of written text module. The filtered questions will help learners to think about the missing points in their answers for open-ended questions or in their essays, because the missing points will be pinpointed by the generated questions.
Furthermore, after the first prototype of the content analysis of written text was implemented, the author came up with another idea: to design and implement, a new hardware and software in order to give to the learners a new interface which allow them to interact with SPEBC and the content analysis module, through speech synthesis and speech recognition. This new hardware and software was called LISTENER.
Previous works about the development of intelligent tutoring spoken dialogue systems have been developed. One of those is ITSPOKE (Litman, et al., 2004). ITSPOKE uses the Why2-Atlas text-based tutoring system as its “back-end”. A student first types a natural language answer to a qualitative physics problem. ITSPOKE then engages the student in a spoken dialogue to provide feedback and correct misconceptions, and to elicit explanations that are more complete. On other hand, Mostow (et. al., 1997) implemented an interactive reading tutor called LISTEN, which listens to children read aloud, and helps them learn to read.
Students will be able to use LISTENER, to record the activities such as the teacher’s explanation, to record an experiment, etc. On other hand, learners will be able to talk with the interface to answer an open-ended question, to dictate an essay, etc. Moreover, students will be able to work in a collaborative way and they will be able to ask LISTENER to function as the discussion moderator. Students will be able to learn anywhere they want, because the portability of this interface. At the same time, LISTENER will help them to comprehend the not understood topics or to have a greater understanding, through a questions and answers process.
The functions of SPEBC, the functions of the content analysis and a spoken interface will be combined. The result of this combination will be LISTENER, a new personalized multimedia interface for ubiquitous learning.
This paper is organized as follows: The first section is the introduction above; the second section presents the antecedents of the problem to be solved; the third section introduces an overview of LISTENER; the fourth section gives the architecture of LISTENER; the final section of this paper provides conclusions.
Antecedents of the Problem
LISTENER, as an improvement and as the spoken interface of SPEBC (Author, et al., 2006) and of the content analysis of written text module, will try to improve, at the same time, the solutions for the problems that SPEBC and the content analysis will try to solve.
SPEBC will try to support teachers and learners in the solution of the following problems: The first one is about the low levels gathered by 15 year old Mexican students in reading literacy (PISA, 2006). The second problem is about the need for tools, which help teachers address the class diversity that can be found in Mexican schools. SPEBC will support teachers and learners in the solution of these problems as follows: SPEBC will generate personalized assessments based on the learners’ background knowledge and external representation types (Giere, R. et al., 2003). SPEBC will include initial, formative and summative assessments. Furthermore, SPEBC will generate multiple-choice and open-ended questions, personalizing the responses according to each learner and knowledge content. Moreover, SPEBC will provide two personalization levels: individual and team (Author, et al., 2007).
LISTENER will go a step further by implementing a mobile and easy to use interface (See Fig. 1) and it will support teachers and learners in the solutions for the two above stated problems, by providing a spoken interface for the questions and answers process. The spoken interface will implement what was found by Koedinger (2000) and by Chi (et al., 1994).
Koedinger (2000) found “that students learn with greater understanding, when they are required to explain their solutions steps, that is, by naming the rule that was used. However, the tutor may be even more effective if students explain their solution steps in their own words and if the tutor helps them, through dialogue, to improve their explanations”.
Moreover, Chi (et al., 1994) concluded, “that learners having articulated an incorrect explanation, they continue to read the next sentence or sequence of sentences in the text. Eventually, the text sentences, because they always present correct information, may contradict knowledge embodied in the incorrect self-explanation. While reading, there are many opportunities whereby what is read contradicts what is being created or existed a priori in one's mental structure. Self-explaining thereby gives rise to multiple opportunities to see conflicts between one's evolving mental structure and the verbal description of it from the text”. (Chi, et al., 1994).
By using LISTENER, students will be able to input spoken answers and essays. LISTENER will be able to ask questions about the learner's spoken inputs. LISTENER will try to support learners in two ways: First, LISTENER will ask them questions based on the text document given as an input in order to evaluate their understanding levels of that given text, in such a way that LISTENER will ask factual questions to the learners about the document that they are studying. Second, LISTENER will evaluate the student’s answers or essays by generating some others questions from each learner’s answers. And these questions will be those, which pinpoint the omitted information in each learner’s input, in such a way that learners will be able to improve the draft of their answers or essays. SPEBC is a domain independent system, therefore, the content analysis module and LISTENER will be also domain independent systems.
Overview of LISTENER
The proposed interface will consist of headphones, microphone and a special device to input the document to be read by the system. Optionally, users will be able to use a video camera with LISTENER.

Figure 1: Second possible scenario in which LISTENER can be used.
Some possible scenarios in which LISTENER will be used are as follows. The first possible scenario takes place in the classroom. Students will use LISTENER to record activities such as the teacher’s explanation, interactions among students when they are solving problems, and details of an experiment. This will be saved as a video clip in a USB flash drive and learners will access them by using a computer to watch the video or by using only LISTENER to listen the audio. LISTENER will be able to apply speech synthesis to generate a written text of the audio of that video clip.
The second scenario is interaction between the student and LISTENER. The learner talks with the interface to answer an open-ended question, to dictate an essay, or just to think aloud expressing ideas about a given topic (See Figure 1). And LISTENER will help learners to complete an answer or essay or clarify their ideas through generation of questions.
The third scenario will support collaborative work among students and LISTENER. One computer with an internet connection will be required for each student. Students will be able to establish a connection from anywhere they are to the classroom or to any other place. Students will able to ask LISTENER to function as the discussion moderator. LISTENER will generate questions about the text documents given as an input or about the conversations among students. Furthermore, each student will be able to use LISTENER as explained in the second scenario so learners will be able to share with other students the personal feedback given to him or her. Moreover, LISTENER will save a record of the discussion and this will be available s text or audio. It will be necessary to implement a specific web application that facilitates collaborative work among students and LISTENER.
The Architecture of LISTENER
The software to be included in LISTENER consists of SPEBC, content analysis module and the natural language processing modules. A brief description of each module is given below:
SPEBC
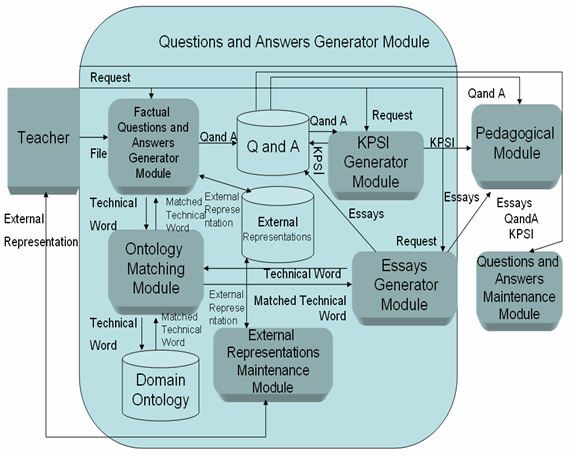
Figure 2: Design of the Questions and Answers Generator Module (Author, et al., 2007)
Figure 2 shows in detail the design of the Questions and Answers Generator Module. The key characteristics of the functionality of this module are as follows.
Teachers will have to request the generation of a KPSI, factual questions, and/or essays. The factual questions generator will generate the questions to be included in KPSI or in an assignment consisting of factual questions. This module will interact with the ontology-matching module in order to identify meaningful tokens such as names, places, models, etc. These data will be saved on the domain ontology database. The factual questions generator will access the representations database, in order to generate personalized responses.
Three kinds of representations (Giere & Moffat, 2003) for each knowledge content will be saved on the representations database. The output of the factual questions generator will be the generated questions and answers and these will be saved on the Q and A database.
The Q and A database will contain essays and KPSI inventories. The essays generator will interact with the ontology-matching module in order to identify the technical words to be included in the essays. The KPSI generator will obtain the questions to be included in the assignment from the Q and A database. These questions are going to be previously generated by the FQG and saved on the Q and A database.
The representations maintenance module will allow to capture and record of representations on a database. The outputs of the FQG, KPSI generator and essays generator will be the input for the pedagogical module. The pedagogical module controls the selection of questions and help teachers in the planning of the generation of assignments. The outputs of the pedagogical module are the assignments” (Author, et al., 2007).
The adaptation process to be included in SPEBC is based on the creation of the knowledge and learner’s models, being the contribution of this approach the incorporation into these models, the required and background knowledge, grade of difficulty and external representation types (Giere, R. et al., 2003). The learner’s personalization factors are: background knowledge and external representations. The knowledge content personalization factors are: required knowledge and external representations. The external representation factor is divided into understanding level, grade of difficulty and representation type (Author, 2007).
Content Analysis of Written Text Module
The content analysis module is based on a check of the learners’ responses, through an automatic generation of questions from their answers, in order to pinpoint the omitted information in each sentence given as an input.
The text given in Table 1 and the questions presented in Table 2, exemplify what the author means with “omitted information”. Table 1 shows a paragraph of an elementary school textbook, from which questions were generated. Table 2 gives a more specific example of the kind of questions generated by the FQGS and filtered by the content analysis prototype. These questions pinpoint the omitted information in the text given as an input.
The content analysis approach consists of filtering and deploying factual questions, which do not have an answer in the text given as an input. In the current implementation state, the content analysis for written text generates only how questions with no answers. The FQGS and the content analysis prototype process only text written in Spanish, therefore, the text presented in Table 1 and 2 are a translation from Spanish to English.
Natural Language Processing Module
The Natural Language Processing techniques to be included in LISTENER are speech synthesis and speech recognition. The approaches to be followed for the implementation of speech synthesis and speech recognition are those given by (Morris, 2000).
Table 1
Text taken from a Natural Science Textbook used
in Mexican Public Elementary Schools

Listener
Figure 3 shows the context diagram designed for LISTENER. Figure 3 shows that the user can input a text document such a paper, dissertation, requirement specification document, etc. And then users will be able to request the generation of questions. SPEBC will generate open-ended, multiple-choice questions, KPSI and essays. Open-ended questions with and/or without answer will be the input for the Content Analysis Module, which will filter and deploy questions without answer to pinpoint the missing points in the learners answers or explanations. After selecting and filtering the open-ended questions with no answers, the content analysis module will give these questions as an input for the Natural Language Processing Module.
Also, SPEBC will provide the generated multiple-choice and open-ended questions, KPSI and essays as the input for the Natural Language Processing Module. The Natural Language Processing Module will perform the speech synthesis and speech recognition processes. And spoken text will be the input and output for the Natural Language Processing Module.
Table 2
Generated questions by the FQGS (Author, et al., 2008)

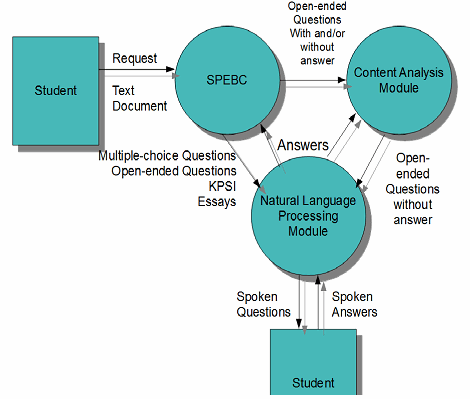
Figure 3: Design of the Context Diagram of LISTENER
Conclusions and Further Research
The present paper introduces a new personalized multimedia interface for ubiquitous learning called LISTENER. This interface will consist of headphones, microphone and of a special device to input the text document to be read. The proposed interface will allow the input and output of data through the processing of speech synthesis and speech recognition, as an alternative media.
A preliminary evaluation of the generated questions was done. The textbook of a 6th grade of a Mexican public elementary school was given as an input. The syntax and semantic of the generated questions were evaluated. From the input, SPEBC generated 255 questions, 28 syntactically incorrect and 33 semantically incorrect. In the evaluated version of SPEBC, the author had to capture the verbs and adverbs included in the textbook. Further research has to be done in order to evaluate the combination of the shallow parser and sentence transformation, which allow the domain independence.
After finishing the implementation of the first prototype of SPEBC, the author is planning to evaluate SPEBC in the classroom. In order to do this, the author is thinking to work with teachers and students of 6th grade of an elementary school. The evaluation process will have two faces: First, the evaluation in the classroom, using a voting system as the interface between SPEBC and the students. And second, the evaluation of SPEBC, when this is used by the learners at home. The effectiveness evaluation results will allow the generation of some useful proposals for teachers.
On other hand, the first prototype for the content analysis was implemented. However, this prototype generates only how questions. Further work need to be done in order to finish the implementation of the prototype which filters and deploys what and why questions. The effectiveness evaluations for the content analysis will be done by evaluating how effective are these questions to pinpoint the omitted information in a given text.
In order to determine the effectiveness evaluation of LISTENER, three scenarios in which LISTENER will be able to be used will be considered. Further work is required in order to implement the speech synthesis and speech recognition approaches. Also, further work is required in order to build the hardware of LISTENER.
LISTENER has a potential application in education; however, its value is not exclusive to education. Researchers and other professionals will be able to use this new interface to help them understand a given topic, to clarify their ideas, etc. LISTENER will be able to really “listen” to users, and it will interact with them through question and answer processes using the same difficulty level, using the same vocabulary, etc., in a personalized way.
References
Authors (2006). Paper Title, e-Learn, 2006, Association for the Advancement in Computing Education, Honolulu, Hawaii.
Authors (2007). Paper Title, Ed-Media, 2007, Association for the Advancement in Computing Education, Vancouver, Canada.
Authors (2008). Paper Title, Ed-Media 2008, Association for the Advancement in Computing Education, Vienna Austria.
Chi, M. T. H., Leeuw, N., Chiu, M. & Lavancher, C. (1994). Eliciting Self-Explanations Improves Understanding, Cognitive Science 18, 439-477. (1994)
Giere, R. & Moffat, B. (2003). Distributed Cognition: Where the Cognitive and the Social Merge. Social Studies of Science 33(2), 1–10.
Koedinger, K. R. (2000).The Need for Tutorial Dialog to Support Self-Explanation (2000) in C. P. Rose & R. Freedman (Eds.), Building Dialogue Systems for Tutorial Applications, Papers of the 2000 AAAI Fall Symposium (pp. 65-73). Menlo Park.
Litman, D & Silliman, S. (2004). ITSPOKE, an Intelligent Tutoring Spoken Dialogue System, Proceedings of the 4th Meeting of HLT/NAACL.
Morris, Tim. (2000). Multimedia Systems: Delivering, generating and interacting with Multimedia, Springer, London.
Mostow, J. & Aist, G. (1997). Project LISTEN: A Reading Tutor that Listens. In World Conference on Educational Multimedia and Hypermedia. Calgary, Canada. Live demonstration.
PISA 2003: Available at: http://www.pisa.oecd.org/pages/0,2987,en_32252351_32235731_1_1_1_1_1,00.html
Tamir, P. & Lunetta, V. N. (1978). An analysis of laboratory activities in the BSCS. Yellow version, American Biology Teacher, 40, 426-428.
About the author
Gabriela Aguilar, PhD. Information Engineering, Shinshu University
Apartado 37 Cintalapa Chiapas, Mexico CP 30400