| June 2006 Index | Home Page |
Editor’s Note: Learning Objects and Learning Management Systems are changing the face of education. Luke Skywalker’s Droid R2D2 in Star Wars had intimate knowledge of everything about its master’s Knowledge, Skills and Attitudes. Its responses were fine tuned to Luke Skywalker’s personality, experience, vocabulary, and modes of communication. Research in Artificial Intelligence is moving us toward this model. Personalized experiential and performance databases are an essential component for excellence in diagnostic-prescriptive technology. State-of-the-art learning systems can be greatly enhanced by algorithms that customize experiences for the individual learner as described in this article.
Towards Personalization and a Unique Uniform Resource Identifier for Semantic Web Users within
an Academic Environment
Muna S. Hatem, Daniel C. Neagu, Haider A. Ramadan
Abstract
With Semantic Web, Personalization is becoming extremely important. The next generation web-based systems are expected to have the capacity to adapt their structure and contents to a particular user. Personalized applications require accurate identification of the user. Expressing identity is one of the core problems that many research efforts address nowadays. The user name or identification number can change over time, written in different languages or spelled in different ways that mislead our search agent or knowledge acquisition algorithm. In addition, many users have the same name and sometimes share the same information for more than one attribute. In the work hereby presented we explore the impact of User Profiles on the Semantic Web. We introduce the concept of Unique Uniform Resource Identifier (UURI) of users; we claim that such UURI is required to uniquely identify each user, this is especially important for multi-lingual Semantic Web resources and further development. We suggest a practical method for creating and maintaining User Profiles for the Semantic Web; the idea is to have UURI for every user and provide users with the ability to update their profiles. The implementation of techniques which assist in recognizing various access patterns and interests of the Web users enable us learning more information about the user to maintain the User Profile. Such techniques will only be effective when User Profile is identified by its UURI. This paper reports on the work in progress to develop a framework for Semantic Web mining and exploration and suggests a practical method towards maintaining UURI for every user.
Keywords: Unique Uniform Resource Identifier (UURI), semantic web, user profile, multi-lingual semantic web, personalization.
Introduction
Traditionally, in knowledge engineering, knowledge acquisition has been regarded as a bottleneck. The International Data Corporation put the number of web pages on the Web at 829 million in 1998 and projected that the number would be 7.7 billion by 2002 [1]. Internet growth has always been greater than predicted; there are now nearly 10 billion web pages on the internet and nearly 10 million web pages are added everyday and this growth is speeding up [2].
The Semantic Web vision [14] demands even more knowledge to be added to Web pages; some of this knowledge is added manually while others are acquired automatically or semi-automatically. The Semantic Web has introduced new promising concepts for Web users; Web pages in Semantic Web are enriched with machine processable information that made it possible to formalize the semantics of web resources. The existence of the Domain Ontology and Annotated Web [23,24] pages has made it possible to extract information from the environment and also relates this information to the concepts described in the domain Ontology.
In a personalized system, the content and/or the structure of the displayed Web page should be dynamically constructed. Personalization normally involves maintaining User Profile (aka User Model). A variety of techniques ranging from simple statistics to machine learning algorithms have been used for personalization and user profiling [25]. Yet, most personalization knowledge that currently exists is actually dealing more with layout customization rather than content.
With the Semantic Web, Personalization has become the crucial point of focus. Learning from the Semantic Web should outperform learning from the current Web; more accurate and more meaningful knowledge can be acquired from the Ontology, the Annotated Web pages and the triple stores. In addition, techniques which assist in recognizing various access patterns and interests of the Web users can capture the user behavior [25]. With Semantic Web, user navigation activities can reveal semantic relationships that can help in learning more validated information about the user than ever before.
Personalization is extremely important for Semantic Web applications in general and for e-business and e-learning applications in particular. Personalization is the process that should be carefully handled at an early stage. We can not only rely on learning from the Semantic Web and prepare for a personalized application; such application is only managed when the system uniquely identifies the resources (in this case, is the user profile that is handled as an important resource).
User identification is a continuous and evolving task. The user name or identification number can change over time, spelled or written in different ways that mislead our search agent or knowledge acquisition algorithm. In addition, many users have the same name and sometimes have the same information for more than one attribute.
The Uniform Resource Locator (URL) [21] is the address that let our software identify and locate a Web page to visit, it is the foundation of the Web, and it can be given to anything on the Web; a whole page, a bookmark on a page or any other object. The problem with the current URL is that anyone can create a URL and in many cases more than one URL is created to refer to the same resources. There have been many attempts to resolve the problem and to prepare for the implementation of the Semantic Web: the Friend Of A Friend (FOAF) [5] project for example implemented a Web based system to help in creating machine processable user profiles for FOAF community, the Resource Description Framework (RDF) vCard [13] is used to help in developing user profiles.
One of the concepts that is getting great importance with the expanding use of internet, e-commerce and e-learning is Web Trust. Web Trust is not only concerned about building customer confidence with a certain website security, privacy, availability, confidentiality, and processing integrity; but it also addresses the confidence of users in un harmful use of Web because of aspects like virus and worm spread or attacks to access private or restricted data. We consider that, in order Personalization to be achieved on the Multi-lingual Semantic Web, first we need to handle the growing need for Web trust. Some techniques like the Digital Signature or the use of some recently announced security tools as the enhance Web Trust Tools presented by Microsoft or Symantec. They both offer everything from remote-controlled antivirus protection to hard drive optimization in one package. These services include 24/7 remote monitoring of the user Personal Computer with automatic updates when needed [4]. Second, even if we managed to securely identify the Web user, we still need a unique identifier that helps us referring to a particular user with high degree of trust and awareness of the user profile.
One of the basic requirements of Semantic Web is adding Annotation to Web pages. These markups are the RDF or OWL instances required for Semantic Web manipulation; for the Semantic Web to become a reality, the accuracy and reliance on stable and accurate references like having UURI is vital. After all, Annotation is a data collection process and therefore, according to the general old rule for data collection processes, data should be collected as close to the source of the data as possible. This rule guarantees its validity for the Annotation process, specially now, when the domain and context are obviously at earlier stages.
Currently there is a need for a document structure that can be used as UURI and provides the following:
Secure and continuous update for the information through web front end that allows the users to access and update their UURI documents.
Hiding the UURI documents from other Internet users.
Multi-lingual names processing: multiple interpretation of the same name should be allowed and maintained in the Knowledge Base (KB).
Allow to include previous names used.
Other names used due to different way in writing the name.
Allow adding previous UURI address in the latest UURI document, this will enable us track users when they move to different work and change the location of their UURI to different domain name.
UURI are to be easily created, flexibly managed and accurately reference individuals.
In the section to follow, we outline the current related work. Our method for building UURI is described in section III. In section IV, we illustrate the UURI allocation method and the system architecture. System implementation is summarized in section V. Conclusions and future work are presented in the last section.
Related Work
Many techniques have been implemented to overcome the Web identification problem in general and the Semantic Web identification problem in particular; some of these techniques can be summarized as follows:
User profile on individual sites
Internet sites like yahoo and Microsoft, for example, present the user with a form to be filled in order to construct its user profile, identified by Username and Password. This profile is then used to provide access to specific services. Although such technique has been used for a considerable amount of time and has been accepted by a considerable number of users, it has many pitfalls as it is risky because the user is giving a third party total control over the user access to the service and private data. An example is that of users proposing the same password for various user accounts (i.e. including Internet bank accounts in the same time with genuine yahoo profiles) to avoid memorizing too many passwords. A break in the security wall to one password might generate a chained security breach. In addition, a user may be requested to fill in many forms required by various service providers. Meanwhile Google has been working on personalization and trying hard to make it work. Google’s Web Alerts let user sign up to receive email alerts when new interesting information are uploaded on the web. Google also provides user with the ability to create search profile to filter results and to create site profile that can help Google to tailor its search. Ask Jeeves has been trying to include personalization based on the user past search, current search and also on other people search.
However, the information collected by service providers about the user does not represent currently useful and reliable resources that fulfill the demands of the Semantic Web and the identification required [15].
FOAF project
The Friend-Of-A-Friend [5] is an application that allows expression of personal information and relationships. This application is based on the idea that states “It’s not what you know, it is who you know” [22]. FOAF is simply an RDF vocabulary where you can use to create your FOAF file on your web server so that the information on this file can be accessed by software. FOAF helps users to locate people with the same interest.
Expressing identity is one of the core problems that FOAF project addressed. FOAF uses e-mail address to identify a particular person. Although this system has been used by some applications, FOAF reliance on email address is risky because, after a period of time, this email address would no longer be valid because the person could change his email address or could use more than one email address.
RDF vCard
The Versit Consortium (VC) developed a comprehensive family of Personal Data Interchange (PDI) technologies. vCard (The Electronic Business Card) is one of these technologies: Versit consortium specification of vCard was published in 1996 [16]. VCard is based on open specifications and interoperability agreements to help meet technology need and allow users to communicate easily and accurately. vCard was specified to carry vital directory information such as name, addresses (business, home, mailing, parcel), telephone numbers (home, business, fax, pager, cellular, ISDN, voice, data, video), email addresses and Internet URLs (Universal Resource Locators). A vCard can also have graphics and multimedia objects and support multiple languages.
The vCard -ready software can run on any computer and have wide industry support [13].
VCard semantic has been represented as RDF vCard document; the purpose is to define an RDF/XML encoding for the format that was initially defined by VC. RDF vCard uses the XML Namespace [XMLNS] to uniquely identify the metadata schema and version as in the URL http://www.w3.org/2001/vcard-rdf/3.0#. It has been created and used over the internet in many different applications. The vCard specifications have been restricted to a well identified attributes and this vCard information is intended to be available to be downloaded by anyone on the internet.
Software Tools Used in our Approach
The implementation and first experiments at this stage are done on local machine where Internet Information Server (IIS) was installed to act as an Internet server. The following main tools are installed and used for the purpose of this current work:
1.1 Jena
Jena is a Java framework for building Semantic Web applications [6]. It is provided by HP Labs Semantic Web Program [7]. Jena is open source that includes programming environment- Application Programming Interface (API)- for OWL and RDF, a rule based inference engine, in-memory and persistent storage such as MySQL and Oracle databases, and the RDQL – a query language for RDF.
Ontology data sources are handled by Jena as ontology model that is created as an extension of the Jena RDF model. This model can either built from an existing Ontology written in RDF or OWL document or it can be constructed by Jena from scratch.
Jena2.3 has been downloaded and installed [6, 11] to prepare the framework for implementation.
1.2 RDF Data Query Language
Jena provided RDF Data Query Language (RDQL) which is a query language for RDF is not a formal standard, although RDQL is widely implemented by RDF frameworks. RDQL allows complex queries to be expressed concisely, with a query engine accessing the data model. RDQL's syntax superficially resembles that of SQL. Some of its concepts will be similar to relational database queries [8].
In this work we use SPARQL [12] that is a query language and a protocol for accessing RDF which is a newer and more sophisticated than RDQL. SPARQL is becoming the standard query language for RDF, it is design by the Data Access Working Group of the World Wide Web Consortium (W3C); SPARQL is built on top of RDQL and it is currently supported by Jena in its latest version 2.3.
SPARQL is "data-oriented" in that it only queries the information held in the models using Select clause to identifies the variables to appear in the query results and WHERE clause that specify a triple pattern . It returns the information needed in the form of a set of bindings or an RDF graph [9]. It provides facilities to construct new RDF graphs based on information in the queried graphs and facilities to extract information in the form of URIs, blank nodes, plain and typed literals, RDF sub graphs.
1.3 MySQL and other Tools
The database management system MySQL [10] has been used to provide for constructing the SQU RDF Repository as a persistent storage. Java is used to write special programs for handling forms submission and other HTTP events. Internet Information Server (IIS) is used for Web server, Oracle client software used to extract information from Oracle Database for initial user profile data collection.
2. UURI allocation method and System Architecture
The case of our study deals with the recently introduced Web portal of SQU , for which Semantic Web abilities are intended to be added. We use a simple, yet powerful technique to allocate UURI for each individual according to the following criteria.
2.1 SQU staff and students
Each staff member and student has a unique identification number allocated by the university. We are going to use this number to uniquely define the initial profile on SQU RDF repository. For example, the UURI of the staff member 5927 will be accessible via staff identification number and password. The static information about individuals is extracted from the university Employee System, Student Information System and WebCT.
If an individual leaves his work at SQU for some other organization, the system treats his UURI as follows:
§ The individual access to his UURI is denied, but all the RDF instances in the KB are kept as they are.
§ In the new organization, a new UURI is created and the user adds a reference to his previous UURI as illustrated in Figure 2. This action is extremely important because every instance in SQU KB will continue to be valid and used; somewhere in the domain ontology there is a fact stating that all UURIs that are associated with a particular individual are equivalent from the system point of view.
2.2 Other individuals or organizations
There are many individuals and organizations the institution (SQU University in our case) collaborate with. There might not be a specific identification number allocated for them at this stage of the implementation. For such people or organizations, we rely on their email address which includes user-name and domain; again this UURI is allocated and the profile is stored on the SQU RDF repository server. http://www.squ.edu.om/sw/D.Neagu@Bradford.ac.uk and http://www.squ.edu.om/sw/96895262118@mms.nawras.com.om are two examples of such UURIs.
The initial information is provided by the squ staff that collaborates with the external staff. The email address or the telephone number used as examples here pay the role of identifier only and do not act as web page locator so we need not do any change to this UURI when the user changes his email address or his other reference number that is used for his UURI. The email address can be updated with the new one but the previous will continue to be used as identifier for SQU domain usage.
2.3 Organizations that implement our proposed system
Organizations that implement the proposed system use the same method for allocating UURI as the one used for SQU staff and students, the only exception is that their UURI web pages are uploaded on their own RDF repository. For example, the University of Bradford (UoB) will implement the proposed system by building the RDF repository in the same way as it is done at SQU. This RDF repository will include facts like Dr. Daniel Neagu (DN) supervises the PhD student Muna Hatem (MH) who is a staff at SQU. Such facts are represented as RDF graph where MH is referred to by her UURI as an object of a property called hasUURI that is defined in the domain ontology. The property has UURI is used to denote that the UURI of this particular resource is on different server.
Internet users can issue a query like “Who supervises/d the PhD research of Muna Hatem (MH)”. The user can be in any of the following different contexts and scenarios:
The user uses SQU portal where it can be found that MH is a staff member: in this case the UURI of MH is known and can directly be used. The software agent will use the RDF triple that is associated with the property supervised to get the required result from UoB RDF repository: Figure 1 illustrates sample RDF annotations.
If the user is using University of Bradford portal, then MH can easily be identified as a student by the software agent and its UURI at the University of Bradford refers to the chosen UURI of MH which may either be on SQU or UoB servers. This particular sample query can be answered without the need to access remote server(s). For most other queries once the UURI is identified, the result will be obtained by the agent following the UURI.
If the search assumes no extra information other than the one that appears in the text of the query, then the query can be issued from anywhere including the global search options on SQU or UoB portals. Here the Agent will search for all individuals with the name Muna Hatem and identifies their UURIs. Then it will look for any UURI associated with the property supervises or supervised. Then the agent will look for facts about the user who issued the query that is related to each of individuals found. The agent uses its own algorithm to filter the results and reach the most appropriate answer to the query; even if the user is anonymous and there is nothing that can be found by the agent about that particular user, there are still many facts that the agent can derive from the context in which this query is issued. These facts can be very helpful for the agent in taking the correct decision about the way the result is filtered.
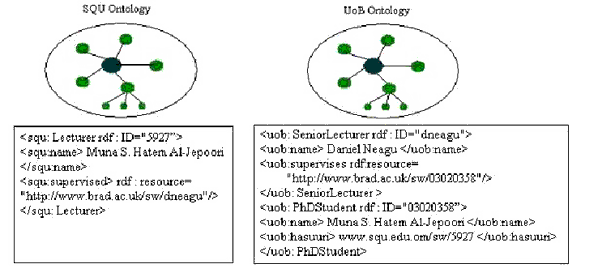
Figure 1: Sample for RDF annotations
In most cases, Internet users will be of the anonymous type though. But one of the aims of the new Internet technology in general and Semantic Web in particular is to become able to uniquely identify each Internet user; this is the key solution to the web identification problem and web security. At the same time this will make the software agents work in a more efficient way.
2.4 Manual Update of User Profiles
A Web-based front end is created to allow users to contribute with metadata. We developed a Java application that can present a familiar Web-based interface to users, accept user data, store corresponding RDF metadata, expose the metadata as HTML document.
At this stage information as to what is the previous UURI, what other names the person previously used, how the name is written in different languages or how it is spelled; such information can be added here to ensure that queries issued with any of the added data items are handled properly once these facts are included in SQU KB. Figure 2 shows a sample UURI document displayed as HTML document to allow updates. Fields marked with * are extracted in the process mentioned in section 4.1 above, other fields are entered by the user
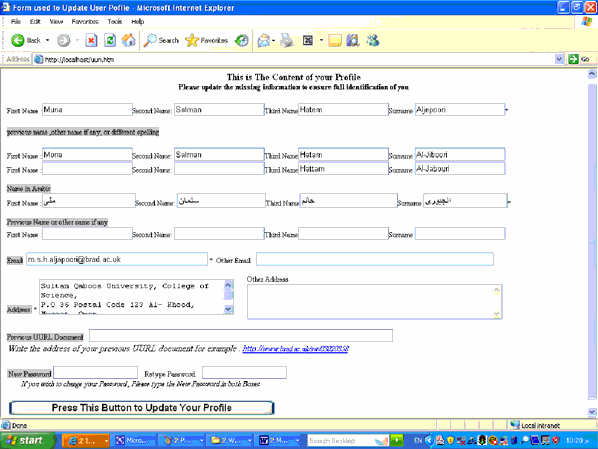
Figure 2: Sample form used for manual update of User Profile
Usage Mining, Learning and Continuous Personalization
Each time the user is involved in an activity or each time this user is refereed by another person’s activity within the SQU domain, some facts are extracted and added to the data base that represent SQU Knowledge Base triple store.
The knowledge extraction program uses Jena API to build and maintain SQU KB, whereas SPARQL is used to extract the required fact whenever it is needed by any of the interrogation program or agent.
At these stages, facts like a person, for example, named Muna Hatem (MH) with ID 5927 knows or relates to some other person called Haider Al-Lawati (HA) because the departmental organization is registered in the Knowledge Base via the graphs loaded from the annotated pages or via usage mining techniques that adds RDF instances to the Knowledge Base. If MH issues a query related to HA, the result will only include required information for this specific person whose ID is (973) and not any other one who holds the same name and works in the same department, or other departments, just like a real world query to a human being asking about some person, the receiver of the query answers normally within the scope known or related to him/her. Relations with other things or persons are established depending on the facts included in the KB. Such information includes the field this person is involved in, country of origin, address, hobbies, research work, collaborations and other learned information. Figure 3 below shows a simplified illustration of the related proposed architecture.
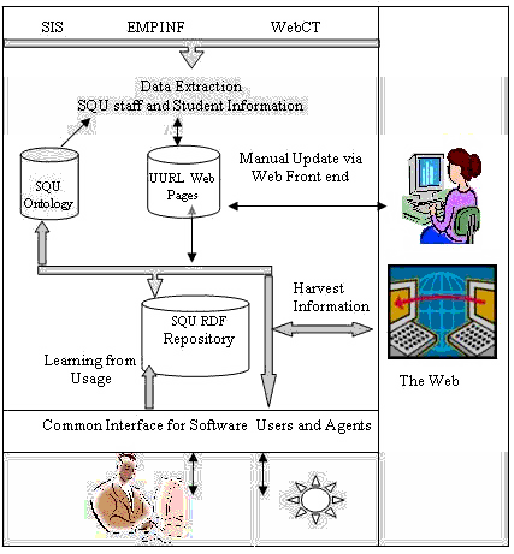
Figure 3: The Architecture of UURI System
3. System Implementation
The prototype system started with the activities that are related to the usage of Jena; the implementation was done on simple data used to construct and examine the model. The practical work implemented so far can be summarized as follows:
The SQU Ontology document has been created using OWL
Sample Web Pages were annotated using the Ontomat annotator
The RDF triples from the annotated pages were extracted into RDF document Data.rdf.
SQU RDF repository was created such that:
A database connection to the data model on MySQL database was created and a model maker for the database backed model that open the connection to the database was created. MySQL backed model squrdf was created and the RDF graphs of the annotated pages were loaded into it from the Data.rdf.
An empty Jena model schema was created and the ontology document was read into it.
An OWL reasoner was bound to the ontology model schema and used to create an inference model.
Sample queries were created and executed
All the properties of the resource found for a particular resource were printed from the inference model.
Figure 4 shows the annotations of UURI 5972 that is explicitly stating all the RDF facts recorded about MH. It includes different interpretations of the first and last name together with the name in Arabic.
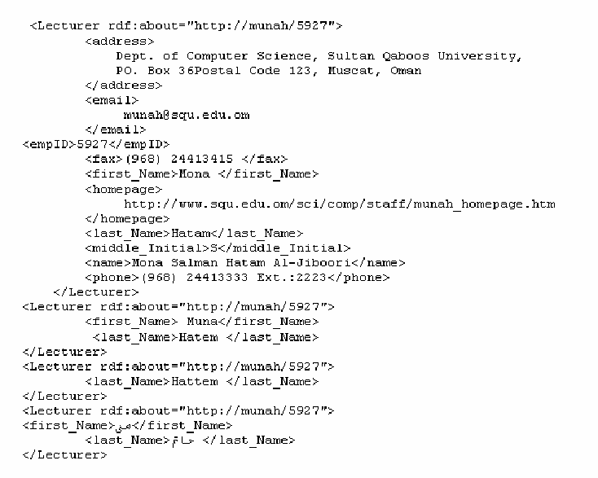
Figure 4: Sample RDF Annotations
For illustration of using the system, let’s suppose that the query is “ What is the fax number of MH “. The original query based on the corresponding UURL identification and the SQU ontology can be analyzed and interpreted to the SPARQL query “SELECT ?x, ?name1 WHERE (?x, <http://munah/squont.owl#empID>, “5927”) (?x, <http://munah/squont.owl#fax>, ?name1 )".

Figure 5: Result of a Sample Query
Figure 5 shows the result of this query. Figure 6 shows that for a person like MH with many different versions of the last_name (Hatem, Hattem, or Hatam), any version used will get the required result since all names belong to the same resource. The figure also illustrates other facts like the list of all the properties inferred or explicitly stated for the resource. It also shows that Jena does not seem to support Arabic language.
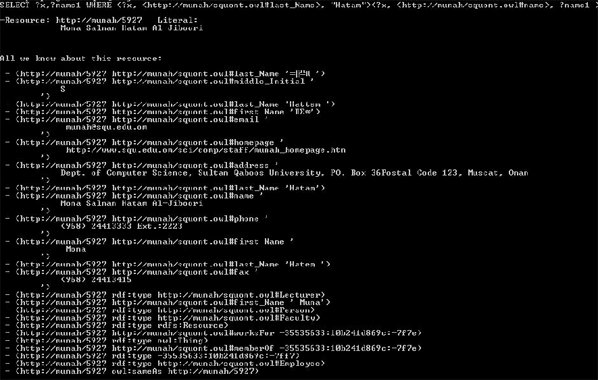
Figure 6: Sample Query and the Properties of a Particular Resource
5. Conclusions and future work
This work represents the first step towards implementing a Semantic Web application for SQU. We found that Jena is an outstanding tool for maintaining the Ontology concepts and RDF instances. Since Jena is based on Java, there are many inference programs and support tools for Jena that enables us to speed up the implementation process. We believe that the second step will easily be implemented on the RDF repository produced.
The UURI suggested in this work is used in the first step of the implementation; that is the Annotation phase of SQU web pages. This UURI will be used in all later stages of the implementation process. The UURL suggested provides for continuous update for the information through web front end that allows the users to access and update their UURI documents. This will especially help in the multi-lingual Semantic Web. UURI are easily created, flexibly managed and accurately reference individuals.
In the future work, the problem of Arabic language and Jena support need to be dealt with. At this stage the work has been implemented on test data. The next step is to complete writing the administrative utility programs, and the user friendly web front end to start the actual implementation on real world data. The RDF repository produced is to be maintained and updated by information learned from the Web; this part of the work will be presented in a separate report.
References:
1. Shadbolt, N.R. and Burton, M. (1990) “Knowledge elicitation” J.R. Wilson & E.N. Corlett, Eds., Evaluation of Human Work: A Practical Ergonomics Methodology, pp.321-345. London: Taylor and Francis.
2. Catledge L.D. and J.E. Pitkow Characterizing browsing strategies in the World Wide Web, Computer Networks and ISDN Systems 26(6): 1065-1073. 1995.
3. H. Ramadhan, Z. Al-Khanjari, A. Al-Hamadani, and S. Kutti. Automatic Construction of the User Web Access Profiles, Transactions on Systems, Vol. 3, 5, 1497-1506, 2004.
4. http://reviews-zdnet.com.com/4520-3513_16-6429627-1.html?tag=fs
5. http://www.foaf-project.org/
6. http://jena.sourceforge.net/
7. http://www.hpl.hp.com/semweb/
8. http://www-128.ibm.com/developerworks/java/library/j-jena/
9. C:\Jenaroot\doc\tutorial\RDQL\index.html
10. http://dev.mysql.com/downloads/
11. C:\Jenaroot\doc\readme.html
12. http://www.w3.org/TR/rdf-sparql-query/#introduction
13. http://www.w3.org/TR/vcard-rdf
14. Ying Ding, Dieter Fensel, Michel Klein, and Borys Omelayenko, The Semantic Web yet another hip, Science Direct - Data & Knowledge Engineering, 2002.
15. http:/dsonline.computer.org/0411/d/oy002b.htm
16. http://www.imc.org/pdi/vcard-21.doc.
17. http://www.w3.org/TR/2006/WD-rdf-sparql-query-20060220/
18. http://jena.sourceforge.net/tutorial/RDF_API/
19. http://www-128.ibm.com/developerworks/java/library/j-jena/
20. file:///C:/Jenaroot/doc/ontology/index.html#cameraExample
21. http://de.wikipedia.org/wiki/Uniform_Resource_Locator
22. http://www-128.ibm.com/developerworks/xml/library/x-foaf.html
23. http://protege.stanford.edu/publications/ontology_development/ontology101-noy-mcguinness.html
24. http://www.sciam.com/print_version.cfm?articleID=00048144-10D2-1C70-84A9809EC588EF21
25. http://www.db-net.aueb.gr/magda/papers/webmining_survey.pdf#
About the Authors
Muna S. Hatem
College of Science, Department of Computer Science
Sultan Qaboos University
PO Box 36, Al-Khod 123,Muscat, OMAN
Daniel C. Neagu
School of Informatics Department of Computing
University of Bradford,
Richmond Road, Bradford, West Yorkshire, BD7 1DP, UK
D.Neagu,m.s.h.aljepoori)@Bradford.ac.uk
Haider A. Ramadan
College of Science, Department of Computer Science
Sultan Qaboos University
PO Box 36, Al-Khod 123,Muscat, OMAN
haiderr@squ.edu.om