| October 2006 Index | Home Page |
Editor’s Note: In October of 2005, Bruce Mann published Part 1 of this study, Making your own educational materials for the Web, in this Journal. Part II draws upon an extensive body of research in learning from images and sounds to develop a cognitive structure and design model called the Sound Structured Function or SSF model. This model is based on learning mechanism for sound and images and differentiates between learning in childre3n and adults.
Making Your Own Materials,
Part II: Multimedia Design for Learning
Bruce L. Mann
Abstract
Part II of Making Your Own Materials describes a cognitive structure for learning from multimedia and a design model, both of which rely on the durability of sound and its natural resistance to interference and forgetting. The cognitive structure is called the attentional control definition of multimedia learning, the design model is called the SSF model.
Keywords: learning, attention, multimedia, SSF model, instructional design, audio, modality.
Multimedia Learning
Learning from multimedia begins when an adult or child watches a graphic or animation, listens to speech, some music or a sound effect, reads some text, focuses his or her attention to learn and send data to and from their long-term memory. Figure 1 is an illustration of the cognitive structure of learning from multimedia.
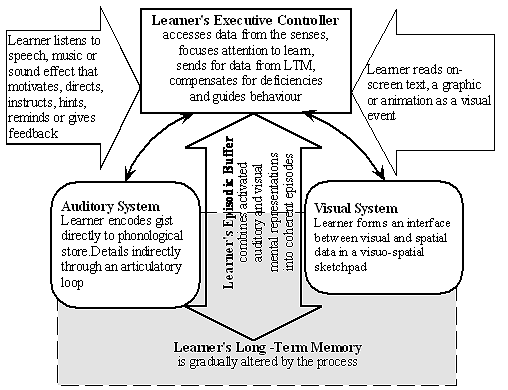
Figure 1. The structure and process of learning from multimedia
according to the attentional control definition of multimedia learning.
Acoustic Image
From listening to a school bell, warning, or hint from a pedagogical agent or teacher’s website, the student encodes its meaning or gist (Brainerd & Reyna, 1990; Estes, 1980; Hildyard & Olson, 1982; Reyna, 1992; Tannen, 1985) as an acoustic image (Baddeley, 1986, p. 44) directly into his or her phonological store as a coherent episode (Baddeley, 2002). Types of multimedia sound includes effects, music or utterances (human or computerized) that can be played from a tape or digitized file, or presented by a talking coach or agent in a computer application or website, a voice-over IP, or pod cast. Acoustic images from sound effects, music and utterances are encoded directly by the student and become more durable and resilient to forgetting than visual traces. “There is clear evidence that short-term memory for material presented in the auditory mode is considerably more durable and resistant to interference from other modalities than is visually-presented material” (Broadbent, Vines & Broadbent, in Baddeley, 1986, p. 42). Further some acoustic images evoke responses in visual areas of the brain, especially in young children (Goswami, 2004). Consider the study by O’Leary and Rhodes (1984) who reported that when babies listened to an audio recording of one woman from a speaker located halfway between two videos of different women speaking simultaneously, the babies preferred to watch the face that belonged with the voice they were hearing. The babies shifted their attention until they associated the auditory and visual events.
Inner Eye
From watching a visual event in multimedia, students form their own interface between the spatial and visual data in visual-spatial memory by re-sketching the graphic or animation through their own visual system, like an inner eye. Types of visual event include sketches, diagrams, static or animated photographs, pictographs, films or video clips, static or moving images, animated gifs, cartoons or computerized tutors, coaches or mentors (human likeness or cartoon), appearing as avatars or agents (static or moving).
Inner Voice, Inner Ear
Whereas sound effects, music and utterances are directly encoded into a phonological store, reading instructions and feedback require mental articulation by the reader. Multimedia learning is dependent on reading and listening, yet reading is not the same as listening, extracting different information from each store by the student’s attentional control system. Analysis of text by the student is first fed into the phonological store by means of sub-vocal speech using an articulatory system, like an inner voice to an ear inner (Baddeley, Gathercole, & Papagno, 1998). The loop plays a crucial role in syntactic learning as well as in the acquisition of the phonological form of lexical items. “The loop system mediates the acquisition of syntactic knowledge, as well as the learning of individual words… not to remember familiar words, but to help learn new words (Baddeley, Gathercole & Papagno, 1998, p. 158, 166).
Whereas good readers can use their context-free word recognition skills, poor and beginning readers use repetitive sentence context. Poor readers gain more from context than good readers, consistent with Stanovitch’s hypothesis (Goldsmith-Phillips, 1989; Nickerson, 1991; Yeu & Goetz, 1994). Young and beginning readers especially, rely on context to read (Goldsmith-Phillips, 1989), showing a heavy reliance on contextual facilitation of word perception because they are less adept at contextual facilitation of comprehension than children in the higher grades, in accordance with Stanovitch’s (1980) interactive-compensatory hypothesis. Young children are not fully capable of mentally articulating instructions and feedback presented in text. Their auditory memory consists of a phonological store without a phonological loop (Gathercole, Pickering, Ambridge & Wearing, 2004). Unarticulated material in young children is analogous to extraneous cognitive load reported in adults (Kalyuga, Chandler & Sweller, 1999; Mayer, Heiser & Lonn, 2001; Sweller & Chandler, 1994). However, when young students read difficult or unfamiliar text they articulate the sound of the words to “hear” themselves say the words. They may experience the common side-effect of a dry throat from sub-vocalizing the sound of words or phrases to be heard by the inner voice. This reliance on reading context decreases as a function of reading development and ability (Goldsmith-Phillips, 1989; Swantes, 1991).
Reports like these about the durability of sound and its resistance to interference and forgetting provide support the inclusion of sound in learning from multimedia, especially in poor readers and young children. However, multimedia learning is more than synaptic responses to sensory stimulation, sound per se is not sufficient to consistently affect learning from multimedia. Student enjoyment of multimedia is either uncorrelated or negatively correlated to learning outcome (Clark, 2001; Clark & Feldon, 2005). Unlike entertainment multimedia, educational multimedia requires reading and listening to instructions and feedback presented in the program or website. Sound must have a purpose or function with the visual events. Given a purpose or function, sound can alert, caution, warn, remind or direct the student to a visual event displayed by a computer program or Internet site. Although sound prompting is permitted direct access to the student’s phonological store, sound per se is not sufficient to consistently effect learning from multimedia. For that reason, the SSF model is distinguished from stochastic roles for sound (in Mann, 1997a). Stochastic sound roles employ a hit-and-miss approach to sound design that describes students’ learning as a function of the playback technology instead of focus attention for long-term learning.
SSF Model
The structured sound function (SSF) model was designed for the teacher or instructional designer to develop a working structure of auditory events with the primary purpose of helping students to control their attention in multimedia (Mann, 1992, 1995a, 1995b, 1997a, 1997b, 2000). The SSF model is comprised of five functions and three structures that when combined, can help students to focus their attention on important visual events in multimedia. Figure 1 shows an illustrated sound design rubric for structuring a sound function with visual events to help students to control their attention.
Sound Function
According to the SSF model, five functions are conceptualized for sound as descriptions of character, place, time, and subject matter when assigned to any visual event displayed in multimedia.
Temporal sound
A temporal sound is an alert, caution, warning or direction about a future event, or a reminder about a past event that is displayed as a visual event in a computer program or at an Internet site. Some examples of temporal sound cueing include: instruction, navigational direction, hinting, feedback and reminders.
POV sound
A point of view (POV) sound describes a particular perspective toward adding sound to help learning from multimedia. When an objective, subjective or performer point of view is presented in sound, it can imply another point of view or more information about the point of view than what is stated or implied in the visual event. Alternatively a POV sound can be prescribed within a character’s personality, showing internal conflict between objective, subjective and performer points of view. POV sound can also be made to differing opinions about political performers, or deeply felt moral, cultural or religious beliefs.

Figure 2. The SSF model, a design rubric to help students focus their attention
on visual events presented in multimedia
Locale sound
A locale sound can fill an informational role when it is associated with a visual event presented in a video clip, graphic, or a paragraph of formatted text. Most often familiar sounds are added to establish a place, real or imaginary. Locale sound in public spaces can transform a passive experience into an active one through an earpiece. Mobile technology can offer users in a city or historic site, or at a public event, a more comprehensive understanding of their surroundings.
Atmosphere sound
Atmosphere sound can provide the context for an event for the listener/viewer in the absence of visual information. A broadcast journalist using streaming technology over the Internet can for example, verbally provide an eyewitness account of a scene after-the-fact. Similarly a voice-over plus a map or photo of the speaker will suffice in lieu of visual evidence of the event.
Atmosphere sound can also provide a feeling about a human condition. Still other times, atmosphere sound can set the mood, as in a celebration or political meeting. Atmosphere sound can easily be misused however, by manipulating the structure of the sound-visual relationship. In a major CD project, for example, where a range of sounds were integrated as the students navigated the information, a student made a choice to see more detail about Thailand and a short musical track was played. The student commented that the sound was not Thai music and decided that the remaining information would not be useful” (Sims, 2006. p 5). Juxtaposing inappropriate music or laughter over a visual event therefore, can undermine the original intent.
Character sound
A character sound refers either to a character’s past, future, or personality, real or virtual. Personality sound refers to the subtext, story spine or tragic flaw in a character. Like personality sound, the character’s past or future sound contains auditory references to a character’s personal, private or public event or idea. Unlike personality sound however, this function does not plumb the depths of the character's psyche.
Structured Sound
Structuring the goal, constancy and density of a sound with a visual event during multimedia learning is a method of associating sound with a visual event. The process is analogous to describing a scientific process or telling a story. The goal of a sound can be either convergent or divergent. The constancy of a sound describes its duration and is either continuous or discontinuous. The density of a sound is the recurring alternation of contrasting idea elements presented as an auditory warning, music or speech and is either massed, spaced or summarized. Of the three structural components, selecting the goal and the constancy are most important. . Discontinuous sound may be sufficient for an easy task or an unfamiliar item. On easy tasks or with familiar items, a student will implement automatic processing (Schneider & Shiffrin, 1977) also known as pre-attentive processing (Treisman, 1986). Pre-attentive processing of easy tasks or familiar items occur in parallel; that is they can handle two or more items at the same time. Under these conditions discontinuous sound may suffice. An example of a continuous temporal reminder would be the repetitive squealing of monkeys in Millie's Math House (EdMark, 1995) when there is no student input.
Prescribing sound for a novice is best served with a convergent goal and continuous constancy. Continuous sound may be especially needed for a difficult task or with an unfamiliar item. On difficult tasks or with unfamiliar items the student must consciously control their mental processing (Schneider & Shiffrin, 1977) to focus their attention (Treisman, 1986). Under these conditions, attention focusing becomes serial; only one task is processed at a time. Learners must consciously focus their attention “to bind the separate features of a stimulus- such as the colour, shape, words, into a unitary object" (Matlin, 1989, p. 57).
To engage the appropriate attentive state, the student must self-initiate the appropriate system of information processing (Borich & Tombari, 1995). Sometimes working memory simply is incapable of highly complex interactions using novel (i.e., not previously stored in long-term memory) elements.
Selecting a temporal sound
Selecting a convergent goal for a temporal sound can help the student to shift his or her attention to a visual event. One example of a convergent goal is a spoken direction about how or where to look to find out how to create a personal objective, or learning outcome to answer a question. An example of a divergent goal for temporal sound is a procedural question spoken during a brainstorming task, such as the spoken reminder to 'click and fully explore' the multimedia environment or website. A divergent goal for sound would deviate, elaborate, or even contradict a visual event. In selecting a temporal sound for novices (i.e., for difficult of unfamiliar task, or poor or beginning readers) use a convergent goal and continuous constancy. That is, using a hint or reminder can cue the student frequently to take action with the information presented in the visual event. The cue might request that the student write or draw something, or discuss an issue with their peers on site or online. When the temporal sound is massed it means that the auditory alert, caution, warning or direction is concentrated within one part of the multimedia program or website. A massed temporal sound occurs during early interaction with the program or website, similar to a news pre-cap, headline or advance organizer. A spaced temporal sound alerts, cautions or reminds the user, such as incoming chat or email. A summarized temporal sound repeats the substance of a longer discussion, like the recap in a television news story.
Selecting a POV sound
Selecting a convergent goal for POV sound aims to resolve a conflict between objective, subjective and performer points of view. An example of a convergent POV sound is in Getting Along, a social learning computer program. A divergent goal for a POV sound is an unresolved difference of opinions among political performers, or among those with deeply felt moral, cultural or religious beliefs. An example of a divergent goal for a POV sound would that generated in the Decisions, Decisions: The Environment (Tom Snyder Productions Inc, 1997) where students learn and apply the lessons of history through role-playing simulation software. Selecting a POV sound for novices requires a convergent goal and continuous constancy. Continuous POV sound is usually a diversity of spoken comments about a visual event. An example would be a lively debate. Discontinuous POV sound can be a distinctive sound that may be a laugh or interruption that reflects a particular opinion. An example would be an infrequent remark that affects the interaction within the multimedia experience. When the POV sound is massed it is typically an auditory interlude or introduction to an event according to an objective, subjective or the performer’s perspective. A summarized POV sound is usually an auditory re-cap or wrap-up of an event according to an objective, subjective or the performer’s perspective. A spaced POV sound is typically an auditory reminder through an event.
Selecting a locale sound
Selecting a convergent goal for a locale sound would immediately reveal the environment or learning context of the multimedia environment. Selecting a continuous locale sound for novice end-users would require a frequent reminder of the environment or learning context. Frequent reminders would preempt the need to explore the context thereby allowing closer engagement with the visual events.
Selecting an atmosphere sound
Selecting a convergent goal for an atmosphere sound aims to provide a desired feeling in the novice user. Selecting a continuous atmosphere sound for a novice would mean unchanging and distinctive recurring messages, warning signals or a musical leitmotif.
Selecting a character sound
Selecting a convergent goal for a character sound aims to restrict the character’s role to something in his or her past or future, or a notable aspect of the character’s personality. Selecting a continuous character sound for a novice describes an ongoing auditory effect, music or utterance (human or computerized) such as a tutor or mentor’s voice that identifies, signifies or personalizes a visual event.
SSF Research
SSF research with graduate students and pre-service teachers learning instructional design (Mann, 1988, 1994, 1995b, 1997b), 7th graders learning fractions (Adams, Mann & Schulz, 2006), 7th graders learning combustion (Mann, Newhouse, Pagram, Campbell & Schulz, 2002), and with 4th and 5th graders learning grammar (Mann, Schulz & Cui, in press) has been promising. Under most conditions, the long-standing need described in the literature for purposeful advice on how to enhance multimedia learning (Barron & Kysilka 1993; Blyth 1960; Buxton 1989; Mayer 2001; Koroghlanian & Klein, 2004; Mayer 2001; Hartman, 1961) can be met with this model.
The SSF model is based on the attentional control definition of multimedia learning. The attentional control definition originated from reviews of the research in several disciplines that developed independently of one another, despite their common field of study (Kemps, De Rammelaere, & Desmet, 2000). Two of the most important influences are the general model of working memory (Baddeley, 1986, 2000; Baddeley & Andrade, 2000; Jefferies, Ralph & Baddeley, 2004) and the supervisory attentional subsystem model (Norman & Shallice, 1980; Shallice, 1982). Although influences do not target multimedia learning directly, they explain why sound is so critical to multimedia learning. According to these cognitive theories, sound is permitted direct access to the student’s phonological store. Taken together the attentional control definition and the SSF model provide mutual support between the psychological description and educational design, analogous to a two-way street, as suggested in the literature (Mayer, 2003).
Research on the SSF model and coincidentally the attentional control definition on which the model is based however, is a departure from the standard position on multimedia learning research. The standard position in multimedia learning research in the literature at present is the cognitive theory of multimedia learning (Mayer 1997, 2001; Mayer & Moreno, 1998). Theoretical support for the cognitive theory of multimedia learning comes primarily from Paivio’s (1986) dual coding theory, which distinguishes between two cognitive systems: verbal and nonverbal. The verbal system includes language and the nonverbal system includes mental imagery. Referential connections between the systems account for the evocation of mental images by language (or language by images). According to the cognitive theory of multimedia learning, meaningful learning occurs when a capable adult selects relevant information from each store, organizes the information into a coherent representation, and makes connections between corresponding representations in each store (Mayer, 1997, 2001).
Whereas the standard position of learning from multimedia has advanced our understanding about its impact on adults and provided an alternative to media comparison research (e.g., Bernard, Abrami, Lou, Borokhovski,Wade, Wozney, Wallet, Fiset & Huang, 2004; Clark & Feldon, 2005), there are shortcomings that reduce its applicability in education. First, this view of multimedia learning is based on experimental studies with adults (i.e., mostly undergraduate psychology majors), not children. Learning for young children is different from learning in adults. Young children are not simply little adults, not capable of reasoning as an adult until they reach the age of 15 (Piaget, 2000). Therefore claims about media effects based on the standard position in multimedia learning should be constrained to learning in adults. Second, instead of studying multimedia learning over several days or weeks as in the attention control definition, the standard approach has relied on impact studies, testing immediately following the treatment. Consequently the educational benefits of the standard position are not as apparent as they could have been had the research used delayed post-testing to examine learning effects over time, in accordance with Sweller’s view (2004) for example, that the main purpose of instruction is to build knowledge in long-term memory. Third, although there is an ongoing initiative to investigate the quantitative effects of off-loading and weeding details from visual events and of increasing signals in sound (Mayer, 2002, 2003), the instructional designer may still be left guessing how much and how often to use sound and how much detail to leave in text, the graphic or animation.
Multimedia Learning and Instruction
The SSF model was designed for the teacher or instructional designer to develop a working structure of auditory events with the primary purpose of helping students to control their attention in multimedia (Mann, 1992, 1995a, 1995b, 1997a, 1997b, 2000). According to the traditional definition of instructional design (Reigeluth, 1983; 1999), the teacher uses instructional methods and media that are best suited to bring about changes in students’ knowledge and skills. Authoring tools such as Movie Maker and Photo Story free to purchasers of Windows XP (MicroSoft Corporation, 2006) can be used to design your own multimedia in science, mathematics, music, language arts, social studies, and other subjects in the curriculum. The traditional definition however, excludes the student from the design process.
One alternative is to implement the SSF model in a constructional design wherein the teacher assumes the student to be an active, changing entity. Hannafin and Hill (2007) introduced the term constructional design to mean a learning environment that enables and supports a student by engaging them in design and invention tasks where knowledge-building tools are provided but concepts are not explicitly taught. Students take an active role in the design of their own educational materials.
A second alternative is that teachers and students work together on projects, such as the class or school website using the SSF model as a job aid to design their own multimedia. A job aid is useful in situations when it is not feasible or worthwhile to commit a procedure to memory. Job aids are often used instead of instruction to save time and money (Rossett & Schafer, 1991), when an individual or group must remember how to complete a task that is infrequently performed, or when the task must be accomplished exactly the same way every time (Boyd, 2005). The individual may understand the task, but the specific sequence of steps in completing the task may be esoteric or difficult to remember (Brown & Green, 2006).
Summary
Part II of Making Your Own Materials describes how students control their attention as they read and listen to multimedia. The SSF model is presented as a heuristic to help students to control their own attention as they read and listen to multimedia and endeavor to form links to their long-term memory. Heuristic is taken here in its functional sense, rather than the computer modeling sense (Bregman, 1989, p.32). It is likely that haptic events such as field experience or hands-on simulation, hand-sensing gloves or simulated reach-in-and-grab technologies that can be downloaded into content, computer applications for user interface navigation, will soon be incorporated into the SSF model. As evolving hardware and software attributes permit more adaptive and non-linear interactions and a higher capacity for differentiating sound from visual and haptic events, the SSF model will continue to be used as a heuristic by teachers and students to control attention, develop coherent episodes, and build the schema in long-term memory.
References
Adams, S., Mann, B.L., Schulz, H. (2006). Can seventh graders learn fractions from a Web-based pedagogical agent? Using comparison groups three times over several weeks. In Bruce L. Mann (Ed.). Selected styles in web-based educational research. (pp. 332-346) Hershey, PA: Idea Group Publishing.
Baddeley, A.D., & Andrade, J. (2000) Working memory and the vividness of imagery. Journal of Experimental Psychology: General, 129, 1, 126-145.
Baddeley, A., & Hitch, G. (1974). Working memory. In G.A. Bower (Eds.). Recent advances in learning and motivation (pp 47-90). New York: Academic Press.
Baddeley, A. (2002). Is working memory still working? European Psychologist. 7(2), 85-97.
Baddeley, A. (1992). Working memory. Science, 255, 556–559.
Barron, A., & Kysilka, M. (1993). The effectiveness of digital audio in computer-based training. Journal of Research on Computing in Education, 25(3), 277-289.
Bernard, R.M. Abrami, P.C., Lou, Y., Borokhovski, E.,Wade, A., Wozney, L., Wallet, P., Fiset, M., & Huang, B. (2004). How does distance education compare with classroom instruction? A meta-analysis of the empirical literature. Review of Educational Research 74 (3), 379-439.
Borich, D., & Tombari, M. (1995). Educational psychology: A contemporary approach. NY: Harper Collins Publishers.
Boyd, S. (2005). Using job aids. ASTD Press.
Brainerd, C., & Reyna, V. (1990). Gist is the grist: Fuzzy trace theory and the new intuitionism. Developmental Review, 10, 3-47.
Brainerd, C. (1993). Forgetting, reminiscence and aging. Paper presented at the Psychology Department Colloquium, Memorial University, St. John's.
Broadbent, D.E., Vines, R., & Broadbent, M. (1978). Recency effects in memory as a function of modality of intervening events. Psychological Research, 40, 5-13
Buxton, W. (1989). Introduction to this special issue on nonspeech audio, Human-Computer Interaction, 4, 1-9.
Case, R. (1985). Intellectual development: Birth to adulthood. New York: Academic Press.
Chandler, P., & Sweller, J. (1991). Cognitive load theory and the format of instruction. Cognition and Instruction, 8, 293–332.
Clark, R.E. (2001). (Ed.). Learning from media: Arguments, analysis, and evidence Greenwich, CT: Information Age Publishing Inc.
Clark, R.E. & Feldon, D.F. (2005). Five common but questionable principles of multimedia learning. In Mayer, R. (Ed.) Cambridge Handbook of Multimedia Learning. (pp.1-23). Cambridge: Cambridge University Press.
Estes, W. (1980). Is human memory obsolete? Psychological Review, 83, 37-64.
Goldsmith-Phillips, J. (1989). Word and context in reading development: A test of the interactive-compensatory hypothesis. Journal of Educational Psychology, 81, 299-305.
Goswami, U. (2004). Neuroscience and Education. British Journal of Educational Psychology, 74, 1-14.
Hannafin, M.J., & Hill, J.R. (2007). Epistemology and the design of learning environments. In R.A. Reiser & J.V. Dempsey (Eds.), Trends and issues in instructional design and technology (2nd ed.). (pp. 53-61). Saddle River, NJ: Merrill/Prentice Hall.
Hartman, F. (1961). Single and multiple channel communication: A review of research and a proposed model. AV Communication Review, 9, 245-267.
Hildyard, A., & Olson, D.R. (1982). On the comprehension of oral vs written discourse. In D. Tannen (Eds.), Spoken and written language: Exploring orality and literacy (pp. 19-24) Norwood, NJ: Ablex Publishing.
Jefferies, E., Ralph, M.A., & Baddeley, A.D. (2004). Automatic and controlled processing in sentence recall: The role of long-term and working memory. Journal of Memory and Language, 51, 623–643
Kalyuga, S., Chandler, P. & Sweller, J. (1999) Managing split-attention and redundancy in multimedia instruction, Applied Cognitive Psychology 13: 351–371.
Kemps, E., De Rammelaere, S., & Desmet, T. (2000). The development of working memory: exploring the complementarity of two models. Journal of Experimental Child Psychology 77, 89–109.
Koroghlanian, C., & Klein, J. (2004). Effect of audio and animation in multimedia instruction. Journal of Educational Multimedia and Hypermedia 13(1), 23-46.
Mann, B.L. (2005). Making your own educational materials for the Web. International Journal of Instructional Technology and Distance Learning 10(2)
Mann, B.L. (2000). Adding Digitized Speech to Web Courses. In Bruce L. Mann (Ed.). Perspectives in Web Course Management. (pp. 135 - 147). Toronto, ON: Canadian Scholar's Press.
Mann, B.L. (1995a). Enhancing educational software with audio: Assigning structural and functional attributes from the SSF Model. British Journal of Educational Technology 26(1), 16-29.
Mann, B.L., Newhouse, P., Pagram, J., Campbell, A. & Schulz, H. (2002). A comparison of temporal speech and text cueing in educational multimedia. Journal of Computer-Assisted Learning, 18(3), 296-308.
Mann, B.L. (1992). The SSF model: Structuring the functions of the sound attribute. Canadian Journal of Educational Communication, 21(1), 45-65.
Mann, B.L. (1995b). Focusing attention with temporal sound. Journal of Research on Computing in Education. 27(4), 402-424.
Mann, B.L. (1997a). Evaluation of presentation modalities in a multimedia system. Computers and Education: An International Journal 28(2), 133-143.
Mann, B.L. (1988). Guidelines for the instructional design of motion picture sound. Masters thesis. Concordia University. Montreal, Canada.
Mann, B.L. (1994). Effects of temporal sound on computer-based learning. Doctoral dissertation. University of Toronto. Canada.
Mann, B.L. (2000). Adding digitized speech to web courses. In Bruce L. Mann (Ed.). Perspectives in Web Course Management. Toronto, ON: Canadian Scholar's Press.
Mann, B.L. (1997b). Shifting attention in multimedia: Stochastic roles, design principles and the SSF Model. Innovations in Education and Training International 34(3), 174-187.
Mann, B.L., Schulz, H., & Cui, J. Multimedia learning in young children: Attentional control, a pedagogical agent and the SSF model of instructional design. Learning and Instruction, in press.
Matlin, M.W. (1989). Cognition. New York: Harcourt, Brace, Janovich.
Mayer, R.E., Heiser, J., & Lonn, S. (2001). Cognitive constraints on multimedia learning: When presenting more material results in less understanding. Journal of Educational Psychology, 93, 187–198.
Mayer, R.E., & Moreno, R. (1998). A split attention effect in multimedia learning: Evidence for dual processing systems in working memory. Journal of Educational Psychology, 90(2), 312-320.
Mayer, R.E. (1997). Multimedia learning: Are we asking the right questions? Educational Psychologist, 32(1), 1-19.
Mayer, R.E. (2001). Multimedia learning. New York: Cambridge University Press.
Mayer, R.E. (2003). The promise of multimedia learning: Using the same instructional design methods across different media. Learning and Instruction 13,125–139.
MicroSoft Corporation (2006). Movie Maker 2.1 for Windows. [Computer software].
MicroSoft Corporation (2006). Photo Story 3.0 for Windows. [Computer software].
Norman, D.A., & Shallice, T. (1980). Attention to action. Willed and automatic control of behavior. University of California San Diego CHIP Report 99.
O’Leary, A., & Rhodes, G. (1984). Cross-modal effects on visual and auditory object perception. Perception & Psychophysics, 35, 565-569.
Paivio, A. (1986). Mental representations: A dual coding approach. Oxford, UK: Oxford University Press.
Piaget, J. (2000). The psychology of the child. New York: Basic Books. (French: Psychologie de l'enfant. Presses. Paris: Presses de Universitaire de France, 1966).
Ragsdale, R.G. (1988). Permissible computing in education: Values, assumptions and needs. New York: Praeger Books.
Reigeluth, C.M. (1983). Instructional design: What is it and why is it? In Charles M. Reigeluth (Ed.). Instructional design models and theories: An overview of their current status, Volume 1 (pp. 3-36). Hillsdale, NJ: Lawrence Erlbaum Associates.
Reigeluth, C.M. (1999). What is instructional design theory? In Charles M. Reigeluth (Ed.). Instructional design models and theories: A new paradigm of instructional theory, Volume 2 (pp. 5-29). Hillsdale, NJ: Lawrence Erlbaum Associates.
Reyna, V. (1992). Reasoning, remembering and their social relationship: Social, cognitive and developmental issues. In M. Howe, C. Brainerd and V. Reyna (Eds.), Development of long term retention. (pp. 103-132). New York: Springer Verlag.
Rossett, A. & Schafer, L. (1991). A Handbook of Job Aids. San Diego: Pfeiffer & Company Publishing.
Shallice, T. (1982). Specific impairments of planning. Philosophical Transactions of the Royal Society London B 298, 199-209.
Sims, R. (2006). Beyond instructional design: Making learning design a reality. Journal of Learning Design, 1(2), 1-7. http://www.jld.qut.edu.au/
Schneider, W., & Shiffrin, R. (1977). Controlled and automatic human information processing: Detection, search and attention. Psychological Review, 84, 1-66.
Swantes, F.M. (1991). Children's use of semantic and syntactic information for word recognition and determination of sentence meaningfuness. Journal of Reading Behavior. (23), 3, 335-350.
Sweller, J., & Chandler, J. (1994). Why some material is difficult to learn. Cognition and Instruction, 12, 185—233.
Sweller, J., van Merrienboer, J., & Paas, F. (1998). Cognitive architecture and instructional design. Educational Psychology Review, 10 (3), 251–296.
Tannen, D. (1985). Relative focus on involvement in written and oral discourse. In D. Olson, N. Torrance and A. Hildyard (Eds.), Language, literacy and learning: The nature of reading and writing. (pp. 124-147). Cambridge: Cambridge University Press.
Tergan, S. (1998). Misleading theoretical assumptions in hypertext/hypermedia research. Journal of Educational Multimedia and Hypermedia 6(3/4), 257-283.
Tom Snyder Productions Inc. (1997) Decisions Decisions: The Environment. [Computer software].
Treisman, A. (1986). Features and objects in visual processing. Scientific American, 255(5), 114B-125.
About the Author
Bruce Mann is a Professor of Education at Memorial University and the author of Perspectives in Web Course Management (2000) and Selected Styles in Web-Based Educational Research (2006). His email is bmann@mun.ca
Contact Details:
Dr. Bruce L. Mann
Memorial University
Faculty of Education
St. John’s, NF Canada A1B 3X8
Email: bmann@mun.ca
Phone: (709) 737-3416 (voice), 737-2345 (fax)