Editor’s Note: Many algorithms are available to prioritize search results of web searches so the most relevant choices are listed first. These algorithms may be based on theoretical constructs, profiles, usage data, mathematical models, or combination of one or more of these aspects. In commerce, group profiles significantly improve selection; in academia, and especially in online learning systems, interactive multimedia, and simulators, learning management systems build comprehensive databases of individual learning behaviors. This enables web mining and recommender systems to make detailed profiles and analyses with greatly enhanced relevance for the individual learner. This is an important step toward the artificial intelligence of R2D2, Luke Skywalker's trusty astromech droid in Star Wars.
The Application of Web-Mining to
Theme-Based Recommender Systems
Haider A Ramadhan, Jinan A Fiaidhi and Jafar M. H. Ali
Abstract
In the world of eLearning where the number of choices can be overwhelming, recommender systems help users find and evaluate items of interest. They connect users with items to “learn” (view, listen to, etc.) by associating the content of recommended items or the opinions of other individuals with the learning user’s actions or opinions. Such systems have become powerful tools in variety of domains including eLearning. This article addresses the techniques used to generate recommendations and focusing on developing a theme-based web-mining application to recommend relevant Web pages to group of learners. This is achieved through automatically discovering various user access patterns from the Proxy log files, and clustering them into themes using a distance based algorithm, namely nearest neighbor algorithm. The paper also discusses experimental evaluation conducted to assess the performance of the algorithm in relation to various features extracted from documents accessed by the users.
Keywords: Web-Mining, Collaborative Filtering, Theme-Based Recommender, eLearning, Clustering.
Introduction
The term Web mining refers to a broad spectrum of mathematical modeling techniques and software tools that are used to find patterns for inferring user intentions while surfing the Web and attempting to pre-fetch documents of interests and eventually to build recommendation models. Recommender systems that incorporate Web and data mining techniques make their recommendations using knowledge learned from the actions and attributes of users. These systems are often based on the development of user profiles that can be persistent (based on demographic or keyword history data), ephemeral (based on the actions during the current session), or both. These algorithms include clustering, classification techniques, the generation of association rules, and the production of similarity graphs through techniques such as Horting’s collaborative filtering.
Several prototype systems were developed in this area, which include WebWatcher (http://citeseer.nj.nec.com/armstrong97webwatcher.html), DiffAgent (Jones 1995), Alexa (Willmot 1999) and Letizia (Lieberman 1995). Several virtual universities introduced recommender systems for their learning products (e.g. myVU http://myvu.vu.edu.au/myVU/index.jsp, VURS http://vu.wu-wien.ac.at/recommender/). However, techniques followed by these systems, though novel, are considered primitive and fail to construct comprehensive models of the user profiles. For example, WebWatcher analyzes hyperlinks in the pages visited by the users and then recommends those links which the system guesses are promising in matching the goal of the session. Letizia attempts to infer user intentions by tracking his/her browsing behavior. Links found on the pages visited by the user are automatically explored by the system and are presented to the user on demand. Hence, the main goal here is to perform some degree of automatic Web exploration by anticipating future page accesses. Obviously, a more solid approach is needed to build the user model which can spell out the various access patterns of the learner.
Searching for Educational Resources
There are presently on the Web countless Learning Objects available for corporate and academic use. Despite the advantages of having access to such ever-growing object repositories, elearning now faces a more pressing challenge: how to find the most appropriate object for a given user/purpose? Common industry standards such as SCORM (Sharable Content Object Reference Model) and IMS (Instructional Management System) facilitate the location of learning objects from a repository by extended search capabilities. For example, the user can search by keyword, date, author, or any metadata field. However, since SCORM defines approximately 60 fields, average users are unlikely to completely specify their needs according to such a large number of attributes. As the granularity of the learning objects decreases and as the size of repositories increases, there will also be a need for much more fine-grained topic descriptions than either SCORM or IMS can provide. Even advanced searches can overwhelmingly return hundreds of thousands of results (Gaaster 1997). Still, this is an improvement from a simple query which could possibly return millions of results. Overall, the process may prove to be inadequate in a society that demands immediate, reliable results in order to meet the demands of their customers. We argue that software can work to alleviate such problems by trying to collaboratively “predict” what users will want rather than expect them to completely define their needs. In this direction, recommender systems research has focused recently on the interaction between information retrieval and user modeling in order to provide a more personalized and proactive retrieval experience and to help users choose between retrieval alternatives and to refine their queries
Historically recommender systems grew from the information filtering research of the late 80s and early 90s which applied information retrieval techniques for personalized information delivery. Examples of early recommender systems include Tapestry (Ki et at 1993), Group Lens (Resnick et al 1994), Fab (Balabonovic and Shoham 1997). The earliest “recommender systems” were content filtering systems designed to fight information overload in textual domains. These were often based on traditional information-filtering and information-retrieval systems. Recommender systems that incorporate information retrieval methods are frequently used to satisfy ephemeral needs (short-lived, often one-time needs) from relatively static databases. Conversely, recommender systems that incorporate information-filtering methods are frequently used to satisfy persistent information (long-lived, often frequent, and specific) needs from relatively stable databases in domains with a rapid turnover or frequent additions. Collaborative filtering (CF) is an attempt to facilitate this process of “word of mouth.” The simplest of CF systems provide generalized recommendations by aggregating the evaluations of the community at large. More personalized systems (Resnick and Varian 1997) employ techniques such as user-to-user correlations or a nearest-neighbor algorithm.
The application of user-to-user correlations derives from statistics, where correlations between variables are used to measure the usefulness of a model. In recommender systems correlations are used to measure the extent of agreement between two users (Breese et al 1998) and used to identify users whose ratings will contain high predictive value for a given user. Care must be taken, however, to identify correlations that are actually helpful. Users who have only one or two rated items in common should not be treated as strongly correlated. Herlocker et al. (1999) improved system accuracy by applying a significance weight to the correlation based on the number of co-rated items. Nearest-neighbor algorithms compute the distance between users based on their preference history. Distances vary greatly based on domain, number of users, number of recommended items, and degree of co-rating between users. Predictions of how much a user will like an item are computed by taking the weighted average of the opinions of a set of neighbors for that item. As applied in recommender systems, neighbors are often generated online on a query-by-query basis rather than through the offline construction of a more thorough model. As such, they have the advantage of being able to rapidly incorporate the most up-to-date information, but the search for neighbors is slow in large databases. Practical algorithms use heuristics to search for good neighbors and may use opportunistic sampling when faced with large populations. Both nearest-neighbor and correlation-based recommenders provide a high level of personalization in their recommendations, and most early systems using these techniques showed promising accuracy rates. As such, CF-based systems have continued to be popular in recommender applications and have provided the benchmarks upon which more recent applications have been compared. This article presents a theme based searching algorithm that enable us to analyze user access patterns, cluster them into groups representing themes or topics, and have them fed into a theme based search engine which would focus retrieving learning resources/objects that are highly relevant to the themes and avoid those objects which are not relevant to the learner topics.
While it may not be currently feasible to extract in full the meaning of an HTML document, intelligent software agents have already been developed which extract semantic features from the words or structure of the document. With the advancement of research in the area of Semantic Networks (Balabonovic and Shoham 1997), this task is expected to enjoy considerable improvement. These extracted features are then used to classify and categorize the documents. Clustering offers the advantage that a priori knowledge of categories is not needed, hence the categorization process is unsupervised. The results of clustering could then be used for various other applications such as searching for other similar documents, organization of the bookmark files, construction of user access models, automatic Web navigation, or to conduct theme based searching as opposed to current key word based searching.
Discovery of User Access Patterns and Themes
The impetus for the work reported in this paper came from our need for a complete user profile which would allow us to design a fully automatic Web navigation system and a theme based search engine. The aim of the former system is to recognize a set of learning pages which are of high interest to the user and then automatically retrieve such pages whenever a change or update is discovered in them. Recently, some work has been reported in this area which captures the pages or the user interests explicitly by asking the users to provide the URLs (Tan 2000). Next the system fetches these pages and constructs a template for each page. The system periodically fetches the pages in the background, constructs the templates, match them with the initial templates stored in the database, and notifies the users when a change in the templates is discovered. Although being a genuine improvement, explicitly capturing the user intentions may not be an efficient way to implement such important tools, an implicit way to achieve that is needed. The aim of the theme based searching is to analyze user access patterns, cluster them into groups representing themes or topics, and have them fed into a theme based search engine which would focus retrieving pages highly relevant to the themes and avoid pages which are not relevant to the user topics.
The second author proposed a framework for searching and recommending learning objects (Fiaidhi, Passi and Mohammed 2004) and currently, the first author is involved in developing two main research projects that are related to the theme-based searching. The first project aims at implicitly constructing a user profile from Proxy server logs and the browser history records. This profile is then compared with the explicit profile manually captured from the user. Both profiles are weighted and integrated to produce a final user model which is used to drive automatic Web navigation system for surfing the Web on the behalf of the user. The second project involves designing a crawler which searches the Web for pages closely relevant to the user themes automatically discovered from the Proxy log files. Our main aim here is to improve the engineering of the theme-discovery process. The purpose of this paper is to find out the optimal keyword and similarity thresholds needed to come up with more focused themes through using clustering techniques. We report the overall process of analyzing user surfing behavior and of constructing user access profile containing a set of themes. We also report an experimental evaluation on the relationship between various feature selections used for clustering the Web pages to come up with an efficient threshold.
For discovering users access patterns, two approaches have been suggested. The first approach (Cheung 1998) attempts to capture the browsing movement, forward and backward, between Web pages in a directed graph called Traversal Oath Graph. In this approach, a set of maximal forward references which represent different browsing sessions are first extracted from the directed graphs. By using association rules, the frequently traversed paths can be discovered. These paths represent most common traversal patterns of the user. In the second approach, user access logs are examined to discover clusters of similar pages which represent categories of common access patterns. In both cases, these patterns can be used in several applications which may include theme or topic based search tools as opposed to current keyword based searches, online catalogues for electronic commerce, and automatic Web navigation to pre-fetch pages of interest which represent user access patterns (Tan 2000).
The task of discovering user access patterns and clustering them into themes is a three-phase process. The input to the process is the user access log saved on the Web proxy server. The log file contains records for each user accessing the Web. Each record in the file represents a page request by user client machine. A typical record contains user id, client IP address, URL of the requested page, the protocol used for data transmission, the date and time of the request, the error code used, and the size of the page (Srivastava et al 1995).
In summary, the purpose of phase one is to clean up the log file and get it converted into a vector form. Each vector contains information such as user id, URL, access time and date. Irrelevant information is eliminated and total time spent on each URL is computed and added to the vector. Next, Generalization is used to consolidate all related URLs into their main home page URL. Frequency of visits and the updated total time spent are also counted and added to the vector.
In phase two, TFIDF (Term Frequency/Inverse Document Frequency (Salton 1999)) algorithm is used to extract keywords from the documents. Since TFIDF normally computes the weights for the words as well, some extra pre-processing was performed to strip the weights from the words. These keywords are taken from the title tag, keyword tags, header tags, meta tags, and emphasized words. According to the threshold used in the experiment (reported in the next section), a certain number of keywords are extracted and added to the initial vector produced in the previous phase. Total time spent and the visit frequency, are the two measures we use to prioritize the words in the vector.
The last phase of the discovery process is to produce the topics of interests from the term vectors. A distance based clustering technique is used to form the topics. The output is a small number of topic vectors representing themes. Each vector contains a predefined number of keywords adjusted in the order according to the time spent and the number of visits.
The distance between any two term vectors is measured by their similarity. The higher the similarity is, the smaller the distance would be. The similarity S(VI,V2) between two term vectors VI and V2 is given by the normalized inner product of VI and V2. When a new term vector is added to a pool of clusterized vectors, its distance from the centroid of all the clusters formed so far will be measured. The new vector will be absorbed by the closest cluster unless its distance is longer than a certain threshold (basically a number of keywords) in which case the new vector forms a new cluster by itself. The centroid of a cluster is a term vector which is the mean of all the vectors in the cluster.
The Experimental Evaluation
Many intelligent software agents have used clustering techniques in order to retrieve, filter, and categorize documents available on the World Wide Web. Traditional clustering algorithms either use a priori knowledge of document structures to define a distance or similarity among these documents or use probabilistic techniques, e.g. Bayesian classification. These clustering techniques use a selected set of words (features) appearing in different documents as the dimensions. Each such feature vector, representing a document, can be viewed as a point in this multi-dimensional space. Many of these traditional algorithms, however, falter when the dimensionality of the feature space becomes high relative to the size of the document space (Kurypis 1997). New clustering algorithms that can effectively cluster documents, even in the presence of a very high dimensional feature space, have recently been reported. These clustering techniques, which are based on generalizations of graph partitioning, do not require pre-specified ad hoc distance functions, and are capable of automatically discovering document similarities or associations .
Clustering in a multi-dimensional space using traditional distance or probability-based methods has several drawbacks (Chang 1998). First, it is not trivial to define a distance measure in this space. Some words are more frequent in a document than others. Taking only the frequency of the keyword occurrence is not enough as some documents are larger than others. Furthermore, some words may occur more frequently across documents. Second, the number of all the words in all the documents can be very large. Distance-based schemes (Jain 1998), such as k-means analysis, hierarchical clustering and nearest neighbor clustering, generally require the calculation of the mean of document clusters. For sets with high dimension, randomly generated clusters may have the same mean values for all clusters. Similarly, probabilistic methods such as Bayesian classification used in AutoClass (Tiherigton 1985) do not perform well when the size of the feature space is much larger than the size of the sample set. However, in the research reported here we do not have a variable length of keywords among documents. The keyword threshold is set fixed for every experiment. In addition, the number of all words in documents is not considered as a criteria for feature selection in our experiments. Hence, it was felt that the distance based clustering would fit our need and would not need to deal with the drawbacks mentioned above.
Our proposed theme-based recommender algorithm is based on a version of the Nearest Neighbor Algorithm (Lu and Fu 1978) with an ad hoc distance similarity metrics. To illustrate the main idea behind this algorithm, we conducted Web search experiments in which a total of 218 web pages/learning objects were retrieved and grouped into four broad learning categories: news, business, finance, and economics. These pages correspond to the clustered vectors. The retrieved pages were downloaded, labeled, and archived. The labeling allowed us to easily calculate an entropy (discussed shortly). Subsequent references to any page were directed to the archive. This ensured a stable data sample since some pages are fairly dynamic in content. A total of five experiments were conducted. Documents were clustered using the Nearest Neighbor Algorithm (NNA) referenced earlier. Only two methods of feature selection were used, namely Keyword Threshold (KT) and Similarity Threshold (ST). The KT refers to the number of words extracted from upper portions of the pages and ranged from 5, 10, 20 and 30 words. The ST ranged from 1 to 5, and was used as a measure to compare the similarity among generated clusters and to consolidate them when a given ST is satisfied. For example, with KT is set to 5 and ST to 3, only 5 keywords are used from each page and those clusters having at least 3 keywords in common are consolidated to form a single cluster.
Our objective is to find the correlation between KT and ST, and their influence on the maximum and mean sizes of the clusters produced. We also aimed at finding out total number of clusters produced across various values of KT and ST. Traditionally, it has been reported that smaller ST values tend to produce few but large clusters with less focus as far as topics are concerned, while large ST values tend to generate large number of clusters which are smaller in size and better in focus. In short, the aim was to find the relationship between dimensionality of clustering and document features. The main difference between the studies reported elsewhere and the reported in this paper has to do with the clustering technique used. Previous studies used either of the following distance based clustering techniques: Bayesian classification, hierarchical clustering, and k-means analysis. Since our near-future aim is to compare major distance based methods, we decided to use NNA. In particular, our goal is threefold:
To verify the inverse relationship between keyword and similarity thresholds.
To assess the impact of the dimensionality, i.e. KT = 5,10, 20 and 30, on the size and number of clusters produced.
To assess the impact of the dimensionality on the level of concentration and focus of the clusters produced.
To compare the performance of NNA with the other three distance based clustering algorithms mentioned above.
With the exception of point 4, all remaining three points are covered by the experiment below. It was hoped that the experiment would assist us in deciding a reasonably efficient threshold for both KT and ST to be used in our research projects which focus on the discovery of user access patterns, automatic web navigation, theme based searching, and intelligent search engines.
The entropy based analysis (kurypis 1997) was used for two main reasons. First, we plan to compare results obtained in our experiment with that reported by other distance based clustering methods referenced above using the same collection of documents used in other experiments. Comparing performance of different algorithms and validating the clustering efficiency is a complex task since it is difficult to find an objective measure of cluster quality. Hence, it was decided to proceed with using entropy as a measure of cluster goodness. Second, one of the main aims of the evaluation reported in this paper is to assess how focused the clusters are in relation to the four broad classes of the categories mentioned above. Entropy comparison is an ideal way to accomplish that.
When a cluster, for example, contains documents from one category only, the entropy value is 0 for the cluster, and when a cluster contains documents from several categories the entropy value of the cluster becomes higher. Hence, lower entropy values tend to suggest more focused clusters in their topics and vice versa. The total entropy is the average entropies of the clusters. We compare the results of the five experiments by comparing their entropies across various feature selection criteria mentioned above (i.e. ST and KT values). As stated earlier, small ST values should produce fewer clusters but with less focus, while larger ST values should produce many clusters but with more focus. This is attributed to the fact that a smaller ST value is expected to make clusters get consolidated (combined) at a higher rate since having few words in common among clusters is more typical than having large number of words in common among clusters.
As an example, assume we have three clusters C1 {x1,x3,x4,x8,x13}, C2 {x4,x7,x13,x14,x15}, and C3 {x1,x4,x8,x15}, where x refers to the keywords. With ST=3, the distance between C1 and C2 would be 2 (two words are in common), between C1 and C3 would be 3, and between C2 and C3 would be 2. As a result, the distance of 2 satisfies the ST value of 3 and hence clusters C1 and C3 would be joined in one cluster with keywords {x1,x3,x4,x8,x13,x15}. However, if ST was set to 2, then all three distances between any two clusters would satisfy the ST value and all three would be joined into one cluster containing all non-duplicate keywords in the three clusters, i.e. unionized. As a result, it would be safe to hypothesize that lower entropy values would be associated with lower ST values, while large ST values would be related to higher entropy values. In fact, our experimental results tend to support this claim.
Table 1: Total and size of clusters
| ST = 1 | ST = 2 | ST = 3 | ST = 4 | ST = 5 | |||||||||||||||
KT | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 |
Total clusters | 53 | 39 | 26 | 19 | 75 | 61 | 53 | 44 | 112 | 83 | 61 | 30 | 164 | 151 | 109 | 79 | 189 | 158 | 119 | 62 |
Average | 34.2 | 58.3 | 71.5 | 125.7 | 132 | |||||||||||||||
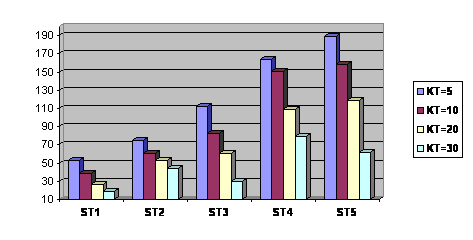
Figure 1: Total number of clusters
Figure 1 and table 1 show the relationship between various KT and ST values.
As shown in Figure 1, the number of clusters tends to increase when the threshold values are near the end of the test range. The results clearly verify the claim that smaller ST values tend to produce few but large clusters with less focus as far as topics are concerned, while large ST values tend to generate large number of clusters which are smaller in size and better in focus.
To show the percentage of overall increase in the number of clusters that is associated with the increase in the ST values, table 1 shows the weighted increase in the number of clusters across all KT values for some ST value. It is noticed that the weighted increase in the number of clusters is steady when ST values increase from 1 to 2. With ST=1, the average number of clusters is 34.2 for all KT values. When ST becomes 2, the average number of clusters produced is 58.3, an increase of 24.1 (70%) over ST=1. When ST becomes 3, average number of clusters produced is 71.5, an increase of 13.2 (23%) over ST=2. With ST=4, the average increase is noticed to be 54.2 (76%) over ST=3. Finally with ST=5, the average increase is 6.3 (5%) over ST=4.
Three main observations can be stated here. First, the number of clusters produced tends to increase across all KT values as the ST values increases. This is shown by Figure 1 and Table 1. Second, this increase is not at the same pace for different KT values. It is noticed that for any ST value, number of clusters tend to be high for smaller KT values and tend to decrease as the KT values increase. Hence, this clearly shows the inverse relationship between ST and KT values. Third, largest average increase in the number of clusters was noticed to be for ST=4 (76%). With ST=5, the average increase drastically dropped to only 5%. This may imply that the similarity threshold value of 4 is the cut off value we seek which tends to produce optimal or semi optimal number of clusters that maintain good focus.
Table 2: Maximum size of clusters
| ST = 1 | ST = 2 | ST = 3 | ST = 4 | ST = 5 | |||||||||||||||
KT | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 | 5 | 10 | 20 | 30 |
Max Size | 65 | 92 | 123 | 205 | 52 | 85 | 111 | 173 | 39 | 68 | 106 | 148 | 19 | 41 | 87 | 130 | 5 | 31 | 79 | 118 |
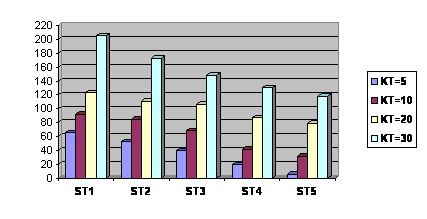
Figure 2: Maximum size of clusters
Figure 2 and Table 2 provide some insights into the maximum size of the clusters produced. Few observations can be made here. First, maximum size of the clusters across all KT values tend to decrease as ST values increase. For example, the decrease in the maximum cluster size from ST=1 to ST=5 for KT=5 is from 65 to 5, hence a reduction of 92%. The reduction, as shown in table 2, for KT=10 is 67%, for KT=20 is 36%, and for KT=30 is 42%. It may be stated that the level of reduction becomes more steady when KT=20, since the next reduction at KT=30 (6%) is not as steep as the reduction from KT=10 to KT=20 which is 31%.
Figure 3 deals with the mean size of clusters. The pattern of the above analysis regarding the maximum cluster size holds valid here as well. Average cluster size drops down as ST values increase. When ST=1, any two vectors having an overlapping keyword would be joined together, hence producing clusters with high average sizes. It can be observed that the effect of the reduction in the average cluster size is visible across all KT values. However, the level of reduction for KT values of 5, 10 and 20 seems to be more steady and stable when compared to that of KT value 30.
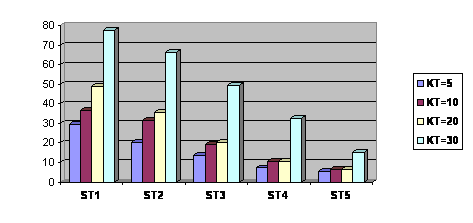
Figure 3: Mean size of clusters
Although cautiously, it could be argued that the keyword thresholds of 10 and 20 along with the similarity threshold of 4 are the cut off values that tend to be recommended by the above results. Very few studies reported on the recommended combination of both threshold values. However, it has been found that KT values of 5 and 20 tend to work best using other distance based clustering methods such as Autoclass (Tiherigton 1985) and, HAC (Duta 1973), and non-distance based methods such as Principal Component Clustering (Moore 2001). As a consequence, it is safe to state that the Nearest Neighboring Algorithm used in this study did not deviate from the path reported by others.
Figure 4 deals with using the entropy-based analysis to get some insights into the focus of the clusters produced in relation to various threshold values and the four categories mentioned earlier. As stated before, when a cluster, contains documents from one category only, the entropy value is 0 for the cluster, and when a cluster contains documents from several categories the entropy value of the cluster becomes higher. Hence, lower entropy values tend to suggest more focused clusters in their topics and vice versa. The total entropy used in the figure is the average entropies of all the clusters.
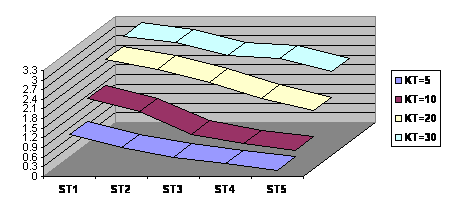
Figure 4: Entropy comparison
Few observations can be noted from the figure. First, lower ST and higher KT values tend to generate clusters with higher entropies, hence implying that such clusters are very general in their topics. This outcome makes sense since in such situation clusters tend to be large in size, and hence combining keywords from documents that belong to several categories. With high ST values, clusters tend to be small in their size mostly contain keywords from documents which come from a certain class. This observation seems to prevail even when KT values are 20 and 30. However, higher KT values still tend to generate clusters with high entropy values, implying that they contain keywords from documents belonging to more than one class, hence are of less focus in their topics. The figure also shows that the gap between entropy values is more evident when KT values change from 10 to 20, and that the gap between 20 and 30 is not as the former one. We can cautiously state that the threshold values of ST=4 and KT=5 or 10 represent the best combination of the thresholds which produce clusters with lower entropy values and hence with better focus. The study used four closely related classes, namely news, business, finance, and economy. It is possible that classes with less relevance could produce different results since un-related classes tend to have fewer keywords common among their documents. Therefore, smaller clusters with better focused keywords should be expected. It is hoped that such claim could also be formally verified.
Similar results have been recently reported but with two main differences (Moore 2001). First, the reported results considered the focus of the clusters across a range of KT values with no relationship with ST values. Second, the algorithm used in the experiment for the clustering was a non-distance based one. In this experiment, it was found that the method, i.e. the PCA algorithm referenced earlier in this paper, worked best with KT values 5 and 20. In our case, KT values 5 and 10 seemed to produce best results. Of course, the quality of the clusters can be better judged by looking at the distribution of class labels among clusters. We hope this task would be completed in the near future.
Conclusion
Recommender systems have been widely advocated as a way of coping with the problem of information overload for knowledge users. Given this, multiple recommendation methods have been developed. However, it has been shown that no one technique is best for all users in all situations. Thus we believe that effective recommender systems should incorporate a wide variety of theme based recommendations. To this end, this article, introduced two types of theme-based recommendations (Keyword Threshold (KT) and Similarity Threshold (ST)). Moreover, other issues were investigated such as the correlation between KT and ST, their influence on the maximum and mean sizes of the clusters produced, and the total number of clusters produced across various values of KT and ST. The experimental analysis shows that our theme based recommender is capable of short listing recommendations once the user themes can be clustered according the keyword threshold in relation with the similarity threshold.
References
Balabanovic M. and Shoham Fab Y. (1997). Content-based collaborative recommendation, Communications of the ACM, 40(3): 66-72.
Breese, J., Heckerman, D., & Kadie, C. (1998). Empirical Analysis of Predictive Algorithms for Collaborative Filtering. In Proceedings of the 14th Conference on Uncertainty in Artificial Intelligence (UAI-98), pp 43-52.
Chang C. (1997). Customizable multi-engine search tool with clustering. Proceedings of 6th International Web Conference.
Cheung D W. (1998). Discovering user access patterns on the Web. Knowledge Based Systems, 10, 463-470.
Duda R. (1973). Pattern Classification and Scene Analysis, Wiley.
Fiaidhi J., Passi K., Mohammed S., (2004). Developing a Framework for Learning Objects Search Engine, 2004 International Conf. on Internet Computing (IC'04) June 21-24, , Las Vegas, Nevada, USA.
Gaaster T., (1997). Cooperative Answering through Controlled Query Relaxation, IEEE Intelligent Systems, Vol. 12, No. 5.
Herlocker, J., Konstan, J.A., Borchers, A., and Riedl, J. (1999). An Algorithmic Framework for Performing Collaborative Filtering. Proceedings of the 1999 Conference on Research and Development in Information Retrieval.
Jain A. (1998). Algorithms for Clustering Data. Prentice Hall.
Jones D. H. (1995).IndustryNet: A model for Commerce on the Web, IEEE Expert, Oct., pp 54-59.
Karypis G. (1997). Multilevel hypergraph partitioning: Application in VLSI domain, Proceedings of ACM/IEEE Design Automation Conference.
Lieberman H., (1995). Letizia: An Agent that Assists Web Browsing, International Joint Conference on Artificial Intelligence, Montreal, August http://lieber.www.media.mit.edu/people/lieber/Lieberary/Letizia/Letizia.html
Lu S. and Fu K.(1978). A sentence-to-sentence clustering procedure for pattern analysis. IEEE Transactions on Systems, Man, and Cybernetics, 8, 381-389.
Moore J. (2001). Web Page Categorization and Feature Selection Using Association Rule and Principal Component Clustering, TR 9405380, Department of Computer Science, University of Minnesota,.
Oki B. M., Goldberg D., Nichols D. and Terry D., (1992). Using collaborative filtering to weave an information tapestry, Communications of the ACM, 35(12): 61-70. Page 11/11
Resnick P., Iacovou N., Suchak M., (1994). Bergstrom and J. Riedl, GroupLens: An open architecture for collaborative filtering of netnews, Proceedings of ACM CSCW’94
Conference on Computer-Supported Cooperative Work, Sharing Information and Creating Meaning, 175-186.
Resnick, P. & Varian, H.R. (1997). Communications of the Association of Computing Machinery Special issue on Recommender Systems, 40(3):56–89.
Srivastava J., Cooley R., Deshpande M., and Tan,P.N. (2000). Web usage mining: Discovery and applications of usage patterns from web data. SIGKDD Explorations, 1(2).
Salton G. (1999). Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer, Addison-Wesley, Reading, Mass., USA.
Tan B. (2000). Web information monitoring for competitive intelligence, Cybernetics and Systems, 33, 3, 225-235.
Titterington D. (1985). Statistical Analysis of Finite Mixture Distributions. John Wiley & Sons.
Willmot D., (1999) Alexa, PC Magazine Online, January (1999).
About Authors
Haider A Ramadhan is an Associate Professor of Computer Science at Sultan Qaboos University, Oman. He received his BS (1985) and MS (1988) in Computer Science from University of North Carolina, and his PhD in Computer Science and AI from the University of Sussex (1993). Dr. Haider’s research interests include software visualization, Web mining, knowledge discovery, and intelligent systems.
Dr. Haider is a member of IEEE, ACM, and BCS. Currently, Dr. Haider is the Chair of the Computer Science Department and the Dean of the College of Science at Sultan Qaboos University. Dr. Ramadhan can be contacted at the Department of Computer Science, Sultan Qaboos University, PO Box 36 Muscat 123 Oman.
haiderr@squ.edu.om.
Jinan A. W. Fiaidhi is a Professor of Computer Science at Lakehead University. She received her graduate degrees in Computer Science from Essex University , UK (1983), and Ph.D. from Brunel University, UK. (1986). She served also as Assistant/Associate/Full Professor at University of Technology, Philadelphia University, Applied Science University and Sultan Qaboos University. Dr. Fiaidhi’s research interests include Learning Objects, XML Search Engine, Multimedia Learning Objects, Recommender Systems, Software Forensics, Java watermarking, collaborative eLearning systems, and Software Complexity.
Dr. Fiaidhi is one of Canada Information Systems Professional (I.S.P.), member of the British Computer Society (MBCS), member of the ACM SIG Computer Science Education, and member of the IEEE Forum on Educational Technology. Dr. Fiaidhi can be contacted at Lakehead University, Department of Computer Science, Thunder Bay, Ontario P7B 5E1, Canada.
Jinan.fiaidhi@lakeheadu.ca
.
Jafar M. H. Ali is an Associate Professor and Department chair at Quantitative and Information System Department, College of Business Administration, Kuwait University. He received his B.Sc degree in 1989 and M.Sc degree in 1991 from Bradley University (USA), majoring in Computer Science. In 1995, he received his doctoral degree from the Department of Computer Science jointly with the Business Graduate School at Illinois Institute of Technology (USA). Jafar’s research interests include Business Applications of Artificial Intelligence, data mining, data warehousing, ethics, end user computing, e-learning, and e-commerce.
Dr. Jafar is a member of AIS, INFOMS, IADIS, and ACM where he published many papers in domestic and international journals. Dr. Jafar contact information is at the Department of Information Systems, Kuwait University, Kuwait.
jafar@cba.edu.kw.